11 Th3
Agentic RAG trong n8n: Lưu trữ và truy xuất mọi loại dữ liệu hiệu quả
Lưu Trữ Mọi Loại Dữ Liệu với Agentic RAG trong n8n
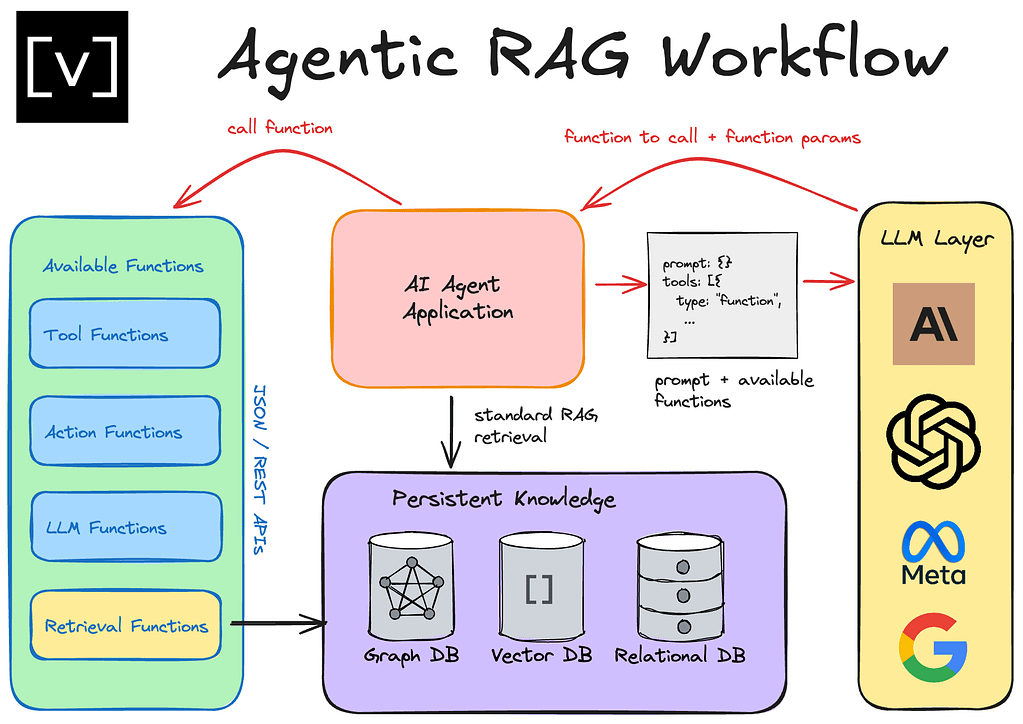
Giới thiệu về Agentic RAG
Ngày nay, cuộc thảo luận về RAG (Retrieval Augmented Generation) đang thay đổi rất nhanh chóng, với sự ra mắt của nhiều mô hình khác nhau có context window lớn hơn. Vậy tương lai của RAG thực sự nằm ở đâu? Chúng ta đã nghe về KAG, Graph RAG, và cả Agentic RAG. Bài viết này sẽ phân tích Agentic RAG một cách chi tiết và dễ hiểu.
Hãy cùng khám phá Agentic RAG và xem một template tuyệt vời cho nó trong n8n. Nhưng trước khi đi sâu vào Agentic RAG, chúng ta cần hiểu rõ RAG là gì.
RAG là gì?
RAG là viết tắt của Retrieval Augmented Generation, về cơ bản là quá trình cung cấp cho agent của bạn quyền truy cập vào một loại cơ sở dữ liệu nào đó để truy xuất thông tin dựa trên truy vấn bạn đưa ra. Agent sẽ lấy lại context đó, tăng cường nó với truy vấn ban đầu, và sau đó tạo ra một câu trả lời chi tiết và cụ thể cho những gì bạn đã hỏi.
Một cách đơn giản để hiểu RAG là hãy tưởng tượng ai đó hỏi bạn một câu hỏi như “Thủ đô của Illinois là gì?” và bạn không biết. Bạn sẽ lấy truy vấn đó, tìm kiếm trên Google, xem kết quả và sau đó trả lời họ. Đó chính là nguyên tắc cơ bản của RAG.
Một quan niệm sai lầm phổ biến là khi nghe đến RAG, chúng ta ngay lập tức nghĩ đến cơ sở dữ liệu vector. Tuy nhiên, RAG, theo nghĩa rộng hơn, chỉ đơn giản là việc lấy context từ một nơi khác và đưa nó trở lại để tạo ra một câu trả lời.
Cách thức hoạt động của RAG truyền thống
Hãy nói về trường hợp sử dụng phổ biến nhất của cơ sở dữ liệu vector. Chúng ta có một loạt các tài liệu, trong trường hợp này, chúng ta chỉ xem xét một tài liệu, nhưng giả sử chúng ta có rất nhiều tài liệu văn bản. Điều chúng ta cần làm là bằng cách nào đó đưa chúng vào cơ sở dữ liệu vector.
Cách thức hoạt động là tài liệu được chia thành các chunk. Đây là điều mà chúng ta có thể thử nghiệm với các kích thước chunk và độ trùng lặp khác nhau. Nhưng nói chung, nó sẽ được chuyển thành các chunk. Ví dụ, chúng ta có thể tạo ra ba chunk từ một tài liệu.
Từ đó, các chunk này được chạy thông qua một mô hình embedding, về cơ bản là biến nó thành một biểu diễn số của dữ liệu, để nó phù hợp với cơ sở dữ liệu vector của chúng ta. Cơ sở dữ liệu vector là một biểu diễn đa chiều của dữ liệu, nơi các vector (các điểm hoặc dấu chấm nhỏ) được lưu trữ ở đâu đó trong không gian này dựa trên các chiều mà chúng được gán khi chạy qua mô hình embedding.
Các chiều về cơ bản chỉ là một loạt các con số và các con số này thực sự được liên kết với ý nghĩa ngữ cảnh dựa trên các từ trong chunk này. Ví dụ, nếu chunk này liên quan đến thông tin công ty, nó sẽ đi lên trên. Nếu chunk này liên quan đến thông tin tài chính, nó sẽ đi sang một bên. Và nếu chunk này liên quan đến thông tin marketing, nó sẽ đi xuống dưới. Chúng được đặt khác nhau trong cơ sở dữ liệu vector và tất cả chúng sẽ dịch chuyển khi có thêm thông tin được đưa vào. Tất cả các vector có liên quan đến nhau sẽ ở gần nhau.
Khi chúng ta thực sự muốn truy vấn cơ sở dữ liệu vector đó, chúng ta thường sử dụng một agent để có được khía cạnh đó của RAG. Quá trình này bắt đầu với một trigger, thường là khi chúng ta đặt một truy vấn cho một agent. Ví dụ, chúng ta hỏi “Tuyên bố sứ mệnh của công ty X là gì?”. Agent sau đó sẽ đọc câu hỏi đó và biến nó thành truy vấn riêng để gửi đến cơ sở dữ liệu vector. Trong trường hợp này, nó chỉ nói “tuyên bố sứ mệnh của công ty X”.
Truy vấn đó được nhúng bằng cách sử dụng chính xác mô hình embedding đã được sử dụng trước đó trong pipeline dữ liệu RAG. Điều này đảm bảo rằng chúng phù hợp trong cùng một không gian gần. Câu hỏi này được nhúng và các chiều của nó được đặt làm một vector gần chunk công ty vì chúng có văn bản tương tự, ý nghĩa tương tự. Sau đó, truy vấn sẽ lấy bốn hoặc sáu vector gần nhất dựa trên cách bạn cấu hình nó. Nó sẽ lấy các chunk gần đó và kéo chúng trở lại.
Sau đó, chúng ta nhận được vector trở lại dưới dạng một chunk và chúng ta có thể đọc nội dung của nó. Chúng ta cũng nhận được truy vấn trở lại. Hai điều này được kết hợp với một LLM để tạo ra phản hồi, đó là đầu ra và đó là kết thúc của quá trình.
Với RAG truyền thống, đó là một truy vấn một lần, lấy mọi thứ trở lại và đây là phản hồi. Tuy nhiên, khi nói đến Agentic RAG, có nhiều lý luận hơn và nó có thể không phải lúc nào cũng là một quá trình một lần.
Agentic RAG: Sự khác biệt là gì?
Agentic RAG vẫn bắt đầu với một trigger, là khi chúng ta đặt một truy vấn cho agent. Nhưng thay vì agent trực tiếp biến điều đó thành một chiều và một vector, và sau đó kéo nó trở lại, nó sẽ xem xét context của những gì nó có và nó sẽ nhận thức rõ hơn về các quyết định mà nó có thể đưa ra để đưa ra truy vấn hiệu quả nhất.
Nó có thể xem xét các cơ sở dữ liệu khác nhau mà nó có quyền truy cập, các lược đồ khác nhau. Ví dụ, chúng ta có thể có rất nhiều không chỉ dữ liệu văn bản, mà còn dữ liệu bảng biểu quan hệ ở đâu đó trong một cơ sở dữ liệu khác. Trong trường hợp đó, chúng ta muốn thực hiện một truy vấn SQL và chúng ta phải xem xét các lược đồ. Nó cũng có thể xem xét tất cả nội dung tệp mà chúng ta có để hiểu rõ hơn. Ví dụ, nếu chúng ta có 10 tài liệu, làm thế nào chúng ta biết truy vấn nào liên quan đến tài liệu nào? Vì vậy, nó có thể đọc nội dung tệp, xem xét các tài liệu thực tế và hiểu các ID tệp hoặc tên của các tài liệu đi qua.
Khi có thông tin đó, nó có thể nói “Tôi sẽ gửi cái này đến cơ sở dữ liệu vector để được nhúng và sau đó đưa vào đó để lấy thông tin trở lại” hoặc nó sẽ hiểu “Dựa trên câu hỏi, tôi sẽ tìm kiếm trong bảng tính dữ liệu bán hàng của chúng ta, bảng tính này sẽ không được vector hóa, chúng ta muốn xem xét một truy vấn SQL. Vì vậy, sau đó tôi sẽ tạo một truy vấn SQL để truy cập đúng cơ sở dữ liệu ở đó”.
Nó sẽ hiệu quả hơn nhiều, phù hợp hơn nhiều và chúng ta cần hiểu tại sao. Tại sao điều này thực sự quan trọng? Có vẻ như việc có một khía cạnh lý luận của một agent trước khi nó gửi truy vấn nghe có vẻ tuyệt vời, nhưng điều đó thực sự có nghĩa là gì?
Ví dụ về tầm quan trọng của Agentic RAG
Hãy quay lại ví dụ về cơ sở dữ liệu vector. Agent sẽ lấy truy vấn của chúng ta và nó sẽ tạo một truy vấn và nó chỉ xem xét các chunk. Điều này sẽ bỏ lỡ context của toàn bộ tài liệu. Ví dụ, chúng ta đang xem xét trong một PDF dài 20 trang và chúng ta chỉ tìm kiếm các chunk cụ thể trong PDF đó. Nhưng nếu chúng ta muốn có thể đọc toàn bộ PDF để lý luận xem chunk nào thực sự có ý nghĩa nhất ở đây, chúng ta sẽ không thể làm được.
Đó là lý do tại sao khi Gemini tung ra context window một triệu, điều đó thực sự đã thay đổi cuộc chơi vì giờ đây một mô hình có thể đọc toàn bộ tài liệu trước khi đưa ra câu trả lời. Dưới đây là một ví dụ thực tế hơn về ý nghĩa của điều này.
Ví dụ, chúng ta yêu cầu agent tóm tắt cuộc họp vào ngày 5 tháng 3, nó sẽ biến điều đó thành một truy vấn như “tóm tắt cuộc họp ngày 5 tháng 3”. Nếu chúng ta đang xem xét một PDF 20 trang về cuộc họp ngày 5 tháng 3, chúng ta sẽ không thể lấy lại tất cả các chunk đó để tóm tắt cuộc họp. Nó chỉ đơn giản là kéo lại năm chunk ngẫu nhiên và sau đó tóm tắt chỉ những chunk đó.
Đó là lý do tại sao chúng ta cần khía cạnh của Agentic RAG. Bây giờ, hãy nói về nó theo nghĩa của dữ liệu bảng biểu. Giả sử chúng ta vector hóa bảng tính này, có các tuần, tổng doanh số, tổng số đơn vị, giá trị đơn hàng, số lượng khách hàng duy nhất, số lượng khách hàng lặp lại. Chúng ta có tất cả thông tin này cho mỗi tuần. Nếu chúng ta hỏi agent tuần nào chúng ta có doanh số cao nhất, nó sẽ biến điều đó thành một truy vấn như “doanh số cao nhất”. Nó sẽ xem xét các chunk và nó sẽ không thực sự có thể lấy được những chunk có doanh số cao nhất. Ngay cả khi nó lấy được, nó về cơ bản chỉ lấy một chunk hàng và sau đó nó sẽ xem xét “Trong chunk này, cái nào cao nhất?”. Vì vậy, nó có thể nói “Đây là 15.000 doanh số, đó là cao nhất trong chunk này và tôi sẽ nói rằng tuần 6 là tổng doanh số cao nhất”.
Mặc dù nếu chúng ta thực sự xem xét dữ liệu, chúng ta có thể thấy rằng tuần 19 cao hơn, tuần 14 cao hơn, tuần 24 cao hơn. Bởi vì agent không thể tạo một truy vấn hiệu quả để xem xét tất cả tổng doanh số hoặc xem xét toàn bộ context của những gì đang diễn ra trước khi nó trả lời. Một ví dụ rất tương tự ở đây là giá trị đơn hàng trung bình của chúng ta là bao nhiêu. Nó về cơ bản sẽ chỉ truy vấn một cái gì đó như “trung bình” hoặc “giá trị đơn hàng” hoặc một cái gì đó tương tự.
Một lần nữa, nó sẽ chỉ lấy một chunk và sau đó nó sẽ nói “Trong chunk này, tôi có thể cố gắng thực hiện phép toán ở đây” và LLM không giỏi toán cho lắm, nhưng nó có thể cố gắng thực hiện phép toán ở đây và tính trung bình các điểm dữ liệu giá trị đơn hàng này và nó sẽ cung cấp cho bạn một câu trả lời. Bạn có thể nghĩ rằng nó đúng, nhưng nó không đúng vì nó sẽ không xem xét tất cả 30 hàng giá trị đơn hàng của bạn. Và bạn biết đấy, rất nhiều lần bạn sẽ có nhiều hơn 30 hàng.
Vì vậy, càng có nhiều dữ liệu bạn đưa vào, thì việc có thể truy vấn SQL một cách chính xác và hiệu quả thông qua những thứ này sẽ càng trở nên cần thiết hơn thay vì dựa vào việc vector hóa agent của bạn để có thể thực hiện những thứ như giá trị đơn hàng trung bình, phân tích số, những thứ như vậy.
Agentic RAG trong n8n
Bây giờ, chúng ta sẽ xem xét một template gần đây của Cole, template Agentic RAG tốt nhất mà tôi từng chơi. Anh ấy làm cho nó siêu dễ dàng vì anh ấy có ba node này, nơi bạn có thể chỉ cần chạy chúng và nó sẽ tạo cơ sở dữ liệu của bạn trong Superbase. Chúng ta đang sử dụng Superbase ở đây. Chúng ta có một bảng tài liệu, đó là vector hóa thực tế của chúng ta, đây là nội dung của các tài liệu khác nhau của chúng ta. Đây là siêu dữ liệu, đây là các embedding. Chúng ta có bảng hàng tài liệu, vì vậy bất cứ khi nào chúng ta muốn tải lên một dạng dữ liệu bảng biểu như CSV hoặc Google Sheets, nó sẽ đưa tất cả các hàng vào đây mà agent có thể truy vấn. Vì vậy, chúng ta có tất cả 30 hàng trong bảng tính của mình ngay tại đây và sau đó chúng ta có siêu dữ liệu tài liệu. Chúng ta đã tải lên ba tệp và chúng ta nhận được cả ba tệp làm mỗi hàng duy nhất, ID của mỗi tệp, tiêu đề của mỗi tệp. Dữ liệu bán hàng là dạng bảng, vì vậy nó kéo lược đồ vào và agent sẽ có thể xem xét lược đồ để tạo truy vấn SQL. Hai cái này đều chỉ là PDF nên không có lược đồ, nhưng dù sao bạn cũng sẽ có thể chạy ba cái đó sau khi bạn kết nối thông tin đăng nhập của mình và bạn sẽ nhận được thiết lập bảng và sau đó phần còn lại của quy trình làm việc sẽ hoạt động cho bạn.
Giống như tôi đã nói, đây có lẽ là template tuyệt vời nhất mà tôi từng thấy trên n8n và xin gửi lời cảm ơn lớn đến Cole. Tất nhiên, nếu bạn muốn tải template này để chơi, nó sẽ có sẵn để tải xuống miễn phí trong cộng đồng School miễn phí của tôi, nhưng tôi cũng sẽ để lại liên kết trong phần mô tả đến video của Cole về nó, anh ấy cũng cung cấp template đó miễn phí và anh ấy có một video nơi anh ấy đi sâu vào những gì đang diễn ra bên trong pipeline này và cả cách anh ấy xây dựng tất cả những thứ này.
Một điều nhanh chóng trong node này, nơi bạn đang thiết lập bảng tài liệu, là cơ sở dữ liệu vector, nếu bạn đã tạo một cơ sở dữ liệu trước đó trong môi trường Superbase của mình, bạn có thể loại bỏ dòng đầu tiên này, cho phép tiện ích mở rộng PG Vector, vì bạn không phải tạo lại nó nếu bạn đã tạo nó trước đó. Ngoài ra, nếu bạn muốn thay đổi tên từ “tài liệu”, bạn sẽ phải thay đổi điều này và sau đó bạn muốn thay đổi các trường hợp khác của từ “tài liệu” trong mã này. Dù sao, bạn sẽ chạy những thứ đó, bạn sẽ được thiết lập và bây giờ hãy trò chuyện với dữ liệu của chúng ta.
Ba tài liệu mà chúng ta có ở đây là dữ liệu bán hàng của chúng ta, đề xuất triển khai AI Green Grass và đề xuất triển khai AI Mountain Top. Tất cả chúng đều ở đây, vì vậy agent phải có thể tìm ra cái nào trong ba tài liệu này tôi cần xem xét. Nếu đó là dữ liệu bán hàng, tôi có thể cần thực hiện truy vấn SQL và nó có các công cụ khác nhau như liệt kê tài liệu, lấy nội dung tệp, truy vấn hàng tài liệu và sau đó tất nhiên là cửa hàng vector Superbase.
Hãy thử một vài truy vấn. Truy vấn đầu tiên là tuần nào có tổng doanh số cao nhất? Nó sẽ cập nhật bộ nhớ của nó, nó sẽ liệt kê các tài liệu, nó đang lấy lược đồ và bây giờ nó đã đi đến việc tạo truy vấn SQL. Nó đã thất bại lần đầu tiên, nó đã cố gắng truy cập lại và bây giờ nó đang lấy nội dung tệp để kéo cái đó trở lại. Những gì chúng ta nhận được là tuần có tổng doanh số cao nhất là tuần 4 với tổng doanh số là 19423. Nếu chúng ta đi vào tài liệu, chúng ta có thể thấy rằng tuần 4, đó là số lượng doanh số chính xác. Rõ ràng tôi có thể thực hiện một hàm Google Sheets để xác minh, nhưng đó là tuần có doanh số cao nhất.
Về cơ bản, nó đã cố gắng liệt kê các tài liệu và nó hiểu “Tôi cần truy cập dữ liệu bán hàng, đây là lược đồ”. Nó đã cố gắng tạo một truy vấn, truy vấn đó đã không thành công ngay lần đầu tiên. Đã có điều gì đó không ổn với dữ liệu số. Trong khi chỉnh sửa, tôi nhận thấy rằng điều này đã báo lỗi vì không có giá trị nào trong tuần 19 cho tổng doanh số, đó là lý do tại sao truy vấn SQL không thành công hai lần. Nhưng thật tốt khi thể hiện chức năng của nó khi tìm nạp nội dung tệp nếu nó báo lỗi. Đó luôn là một giải pháp an toàn tốt. Đó là lý do tại sao nó báo lỗi nếu ai đó tò mò.
Nó đã cố gắng tạo một truy vấn một lần nữa và nó đã báo lỗi một lần nữa. Vì vậy, giải pháp an toàn của nó là “Tôi sẽ chỉ lấy tất cả nội dung tệp của ID này” và nó biết lấy ID này vì trước đó nó đã liệt kê các tài liệu và nó đã thấy ID của bảng bán hàng. Từ đó, nó có thể xem dữ liệu này, có thể xem tất cả dữ liệu và sau đó nó có thể đưa ra phản hồi, đó là tuần 4 có số lượng doanh số cao nhất.
Chỉ để cho bạn thấy rằng truy vấn SQL hoạt động, hãy thử một truy vấn khác. Giá trị trung bình số lượng khách hàng duy nhất của chúng ta mỗi tuần là bao nhiêu? Nó sẽ truy cập bộ nhớ, nó đang liệt kê các tài liệu để lấy lược đồ đó. Bây giờ nó sẽ cố gắng tạo một truy vấn, chúng ta đã nhận được màu xanh lá cây và chúng ta đã nhận được giá trị trung bình số lượng khách hàng duy nhất mỗi tuần là khoảng 171. Chúng ta sẽ thực hiện một phép tính nhanh, chúng ta sẽ lấy trung bình số lượng khách hàng duy nhất. Câu trả lời là 171,07, chính xác là những gì chúng ta nhận được ở đây.
Những gì nó đã làm là nó đã có thể tạo truy vấn này. Những gì nó đang làm là nó đang chọn giá trị trung bình trong số tất cả các khách hàng duy nhất từ tài liệu chính xác và sau đó nó đang thực hiện điều đó bằng một phép toán truy vấn SQL thay vì LLM dựa vào, thay vì chúng ta dựa vào LLM để thực hiện phép toán. Đó là lý do tại sao chúng ta nhận được câu trả lời chính xác ở đây, đó là những gì chúng ta đã thấy trong Google Sheets của mình. Một truy vấn nữa chúng ta sẽ thực hiện là tổng số đơn vị được bán từ tuần 4 đến tuần 10 là bao nhiêu? Chúng ta sẽ gửi truy vấn đó và nó sẽ lại liệt kê các tài liệu để lấy lược đồ và bây giờ nó sẽ tạo truy vấn SQL đó. Chúng ta đã nhận lại điều đó và nó nói tổng số đơn vị được bán từ tuần 4 đến tuần 12 là 2139. Hãy thực hiện một phép tính nhanh tổng số đơn vị được bán từ tuần 4 đến tuần 10 và chúng ta nhận được 2139, chính xác là những gì agent của chúng ta đã nói. Nó đã truy vấn nó bằng cách về cơ bản nói “Tôi muốn tính tổng số đơn vị được bán từ ID này và tuần phải nằm giữa 4 và 10”.
Bây giờ, hãy xem liệu chúng ta có thể truy cập cơ sở dữ liệu vector để kéo lại một số thông tin về đề xuất triển khai AI Green Grass, không phải Mountain Top. Chúng ta sẽ nói “Điều gì đang diễn ra trong email và Outreach tự động trong dự án Green Grass của chúng ta?”, chúng ta sẽ xem nó sử dụng những công cụ nào. Đầu tiên, nó đã đi thẳng đến cơ sở dữ liệu vector Superbase. Email Outreach trong dự án Greengrass nhằm mục đích tự động hóa và nâng cao hoạt động Outreach bán hàng và trình độ chuyên môn của khách hàng tiềm năng thông qua tự động hóa dựa trên AI. Chúng ta có các mục tiêu là hợp lý hóa tương tác. Nó đã cung cấp cho chúng ta toàn bộ phạm vi công việc và nó đã cung cấp cho chúng ta kết quả mong đợi, dòng thời gian dự án. Nó đã cung cấp cho chúng ta một phần thông tin khá chi tiết.
Bây giờ, hãy xem những gì nó đã làm liên quan đến truy vấn mà nó đã gửi đến Superbase. Những gì nó đã làm là nó đã truy vấn “email Outreach dự án green grass”. Nó đã có thể kéo lại chunk này từ green grass, nó đã có thể kéo lại các kết quả mong đợi và kéo lại thông tin này về dự án green grass của chúng ta.
Chúng ta sẽ thử một điều khó hơn một chút. Chúng ta sẽ nói “Dự án nào có chi phí ước tính là 50.000?”. Trong Green Grass là 25, còn Mountain Top là 50. Chúng ta sẽ gửi điều này đi và chỉ xem agent nghĩ gì về nó. Nó đã đi thẳng đến Superbase và có vẻ như đó đã là câu trả lời của nó và nó nói dự án với chi phí ước tính là 50k là đề xuất triển khai AI Mountain Top. Nó nói “chi phí ước tính dự án 50.000 đô la” và nó đã có thể kéo lại các chunk dựa trên truy vấn đó và sau đó nó có thể xác định rằng đó là dự án Mountain Top.
Hãy thử một điều nữa. Chúng ta sẽ nói “Hãy cho tôi một bản tóm tắt ngắn gọn về tất cả các dự án của chúng ta”. Đó không phải là dấu chấm hỏi, đó là một lệnh. Nó đang suy nghĩ về nó lâu hơn. Những gì nó đã làm là nó đã sử dụng bộ nhớ của nó. Chúng ta sẽ xóa bộ nhớ trong Postgress, chúng ta đã xóa lịch sử trò chuyện trong NAD End của chúng ta. Bây giờ nó không có bộ nhớ để làm việc và chúng ta sẽ nói “Hãy cho tôi một bản tóm tắt ngắn gọn về tất cả các dự án của chúng ta”. Nó đang truy cập vào cửa hàng Vector Superbase, tôi nghĩ đó là điều duy nhất nó sẽ làm ở đây. Hãy xem điều này chính xác đến mức nào. Chúng ta có green grass, nó đã cung cấp cho chúng ta tên dự án, phạm vi công việc, ngăn xếp văn bản và nó đã cung cấp cho chúng ta điều tương tự cho Mountain Top, ngoại trừ nó không cung cấp cho chúng ta một ngăn xếp văn bản. Nếu chúng ta đi đến nhật ký, chúng ta đi đến cửa hàng Vector Superbase, nó nói “tóm tắt tất cả các dự án”.
Đây là một trong những hạn chế về chính xác những gì chúng ta đã nói trước đó với việc chia chunk vì nó đã nhận lại bốn chunk và nó đã làm bốn vì ở đây chúng ta đặt giới hạn là bốn. Nếu chúng ta đặt giới hạn này thành 10, nó sẽ kéo lại 10 chunk và nếu chúng ta thực hiện lại điều này, chúng ta sẽ thấy rằng chúng ta có thể nhận được nhiều chi tiết hơn về các dự án của mình vì nó có nhiều thông tin hơn để làm việc. Những gì chúng ta muốn làm là có thể sử dụng nhận nội dung tệp để nhận tất cả thông tin dựa trên ID. Chúng ta muốn nó có thể liệt kê tài liệu và sau đó nhận nội dung tệp để kéo lại hai ID đó và nhận mọi thứ. Như bạn có thể thấy, điều này chi tiết hơn bây giờ vì chúng ta đã tăng giới hạn. Nhưng có thể khó khiến AI làm điều đó vì nó về cơ bản không gây ra lỗi.
Những gì chúng ta sẽ làm là nhắc nó một cách rõ ràng cung cấp cho tôi bản tóm tắt về các dự án bằng cách sử dụng công cụ git file contents. Nó đang liệt kê các tài liệu, bây giờ nó sẽ truy cập vào nhận nội dung tệp và bây giờ chúng ta sẽ có nó kéo lại hai nội dung tệp. Như bạn có thể thấy, nó đang nhận tất cả thông tin về hai dự án của chúng ta và bây giờ nó đang cố gắng xây dựng điều đó thành một bản tóm tắt ngắn gọn cho chúng ta. Chúng ta sắp nhận được câu trả lời đó. Chúng ta có nội dung đầy đủ thực tế của dự án ở đó và nếu chúng ta nhấp vào đây trong nhật ký, chúng ta sẽ thấy trước tiên nó đã liệt kê các tài liệu, vì vậy nó có thể nói đây là ID cho dự án của chúng ta, đây là ID cho dự án thứ hai của chúng ta và bây giờ tôi sẽ nhận nội dung tệp. Như bạn có thể thấy, nó đã nhận được mọi thứ vì nó đã lọc theo ID này và sau đó nó đã thực hiện lại điều đó cho dự án thứ hai, lọc theo ID này và bây giờ chúng ta có tài liệu đầy đủ thực tế.
Đó là những gì chúng ta muốn làm và thật khó để khiến AI làm điều đó mà không có lỗi thực tế ở đây. Nhưng như bạn có thể thấy, đó là cách nó có thể xem xét các dự án, lấy các ID đó và sau đó nhận lại mọi thứ. Đó là những gì chúng ta muốn. Giống như tôi đã nói, siêu siêu template tuyệt vời. Nó thậm chí còn có một pipeline RAG đầy đủ ở đây, xử lý các tệp PDF, văn bản hoặc bất kỳ dữ liệu bảng biểu nào và nó sẽ tạo các hàng đó và nó sẽ tổng hợp nó và vẫn đẩy nó vào. Siêu siêu template tuyệt vời ở đây. Xin gửi lời cảm ơn lớn đến Cole một lần nữa.
Vui lòng nhấn vào biểu tượng kênh hỗ trợ dưới đây nếu Bạn vẫn cần thêm thông tin/ Hỗ trợ:






Tìm kiếm tức thì các thông tin tại website: tranxuanloc.com
Mẹo tìm kiếm: "Từ khóa cần tìm kiếm" site:tranxuanloc.com để tìm được kết quả chính xác trên công cụ tìm kiếm của google[wd_asp id=1]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}