Nếu bạn đã cài đặt Docker và Docker-Compose, bạn có thể bắt đầu từ bước 4.
Bạn có thể tìm thấy các cấu hình Docker Compose cho các kiến trúc khác nhau trong kho lưu trữ n8n-hosting.
Điều kiện tiên quyết về kiến thức tự lưu trữ
Việc tự lưu trữ n8n yêu cầu kiến thức kỹ thuật, bao gồm:
Thiết lập và cấu hình máy chủ và container
Quản lý tài nguyên ứng dụng và khả năng mở rộng
Bảo mật máy chủ và ứng dụng
Cấu hình n8n
n8n khuyến nghị tự lưu trữ cho người dùng thành thạo. Sai sót có thể dẫn đến mất dữ liệu, các vấn đề về bảo mật và thời gian ngừng hoạt động. Nếu bạn không có kinh nghiệm quản lý máy chủ, n8n khuyên bạn nên dùng n8n Cloud.
Các phiên bản mới nhất và tiếp theo
n8n phát hành một phiên bản phụ mới hầu hết các tuần. Phiên bản latest dành cho việc sử dụng sản xuất. next là bản phát hành gần đây nhất. Bạn nên coi next như một phiên bản beta: nó có thể không ổn định. Để báo cáo sự cố, hãy sử dụng diễn đàn.
Điều này có thể khác nhau tùy thuộc vào bản phân phối Linux được sử dụng. Bạn có thể tìm thấy hướng dẫn chi tiết trong tài liệu Docker. Ví dụ sau đây dành cho Ubuntu:
Nếu bạn dự định đọc/ghi các tệp cục bộ bằng n8n (ví dụ: bằng cách sử dụng nút Đọc/Ghi tệp từ đĩa, bạn sẽ cần định cấu hình thư mục dữ liệu cho các tệp đó tại đây. Nếu bạn đang chạy n8n với tư cách người dùng root, hãy thêm phần này bên dưới volumes cho dịch vụ n8n:
Nếu bạn đang chạy n8n với tư cách người dùng không phải root, hãy thêm phần này bên dưới volumes cho dịch vụ n8n:
- /home/<YOUR USERNAME>/n8n-local-files:/files
Giờ đây, bạn sẽ có thể ghi các tệp vào thư mục /files trong n8n và chúng sẽ xuất hiện trên máy chủ của bạn lần lượt trong /local-files hoặc /home/<YOUR USERNAME>/n8n-local-files.
# Tên miền cấp cao nhất để phục vụ từ đó
DOMAIN_NAME=example.com
# Tên miền con để phục vụ từ đó
SUBDOMAIN=n8n
# DOMAIN_NAME và SUBDOMAIN kết hợp quyết định vị trí có thể truy cập n8n
# ví dụ trên sẽ cho kết quả: https://n8n.example.com
# Múi giờ tùy chọn để đặt múi giờ nào được Cron-Node sử dụng theo mặc định
# Nếu không đặt, giờ New York sẽ được sử dụng
GENERIC_TIMEZONE=Europe/Berlin
# Địa chỉ email để sử dụng cho việc tạo chứng chỉ SSL
SSL_EMAIL=user@example.com
Giờ đây, n8n sẽ có thể truy cập được bằng cách sử dụng tổ hợp tên miền con + tên miền được xác định ở trên. Ví dụ trên sẽ cho kết quả: https://n8n.example.com
n8n sẽ chỉ có thể truy cập được bằng cách sử dụng https chứ không phải bằng cách sử dụng http.
Hướng dẫn lưu trữ này sẽ hướng dẫn bạn cách tự lưu trữ n8n trên một droplet của DigitalOcean. Nó sử dụng:
Caddy (một reverse proxy) để cho phép truy cập vào Droplet từ internet. Caddy cũng sẽ tự động tạo và quản lý chứng chỉ SSL / TLS cho phiên bản n8n của bạn.
Docker Compose để tạo và xác định các thành phần ứng dụng và cách chúng hoạt động cùng nhau.
Các kiến thức cần có để tự lưu trữ
Tự lưu trữ n8n đòi hỏi kiến thức kỹ thuật, bao gồm:
Thiết lập và cấu hình máy chủ và container
Quản lý tài nguyên ứng dụng và khả năng mở rộng
Bảo mật máy chủ và ứng dụng
Cấu hình n8n
n8n khuyến nghị tự lưu trữ cho người dùng có kinh nghiệm. Các sai sót có thể dẫn đến mất dữ liệu, các vấn đề bảo mật và thời gian chết. Nếu bạn không có kinh nghiệm quản lý máy chủ, n8n khuyến nghị n8n Cloud.
Phiên bản mới nhất và phiên bản tiếp theo
n8n phát hành phiên bản phụ mới hầu hết các tuần. Phiên bản latest dành cho sử dụng trong môi trường production. next là bản phát hành gần đây nhất. Bạn nên coi next như một bản beta: nó có thể không ổn định. Để báo cáo sự cố, hãy sử dụng diễn đàn.
Khi tạo Droplet, DigitalOcean yêu cầu bạn chọn gói. Đối với hầu hết các mức sử dụng, gói CPU dùng chung cơ bản là đủ.
Khóa SSH hoặc Mật khẩu
DigitalOcean cho phép bạn chọn giữa xác thực bằng khóa SSH và mật khẩu. Khóa SSH được coi là an toàn hơn.
Đăng nhập vào Droplet của bạn và tạo người dùng mới#
Phần còn lại của hướng dẫn này yêu cầu bạn đăng nhập vào Droplet bằng thiết bị đầu cuối với SSH. Tham khảo Cách kết nối với Droplets bằng SSH để biết thêm thông tin.
Bạn nên tạo một người dùng mới, để tránh làm việc với tư cách người dùng root:
Đăng nhập với tư cách root.
Tạo người dùng mới:
Làm theo hướng dẫn trong CLI để hoàn tất việc tạo người dùng.
Cấp quyền quản trị cho người dùng mới:
usermod -aG sudo <tên người dùng>
Bây giờ bạn có thể chạy các lệnh với đặc quyền siêu người dùng bằng cách sử dụng sudo trước lệnh.
Docker Compose, n8n và Caddy yêu cầu một loạt các thư mục và tệp cấu hình. Bạn có thể sao chép chúng từ kho này vào thư mục home của người dùng đã đăng nhập trên Droplet của bạn. Các bước sau sẽ cho bạn biết tệp nào cần thay đổi và những thay đổi cần thực hiện.
Để duy trì bộ nhớ cache của Caddy giữa các lần khởi động lại và tăng tốc thời gian khởi động, hãy tạo một volume Docker mà Docker sử dụng lại giữa các lần khởi động lại:
n8n thường hoạt động trên một tên miền phụ. Tạo bản ghi DNS với nhà cung cấp của bạn cho tên miền phụ và trỏ nó đến địa chỉ IP của Droplet. Các bước chính xác cho việc này tùy thuộc vào nhà cung cấp DNS của bạn, nhưng thông thường bạn cần tạo bản ghi “A” mới cho tên miền phụ n8n. DigitalOcean cung cấp Giới thiệu về thuật ngữ, thành phần và khái niệm DNS.
n8n chạy như một ứng dụng web, vì vậy Droplet cần cho phép truy cập đến lưu lượng truy cập trên cổng 80 cho lưu lượng không an toàn và cổng 443 cho lưu lượng an toàn.
Mở các cổng sau trong tường lửa của Droplet bằng cách chạy hai lệnh sau:
n8n cần một số biến môi trường được thiết lập để chuyển đến ứng dụng đang chạy trong container Docker. Tệp .env ví dụ chứa các phần giữ chỗ bạn cần thay thế bằng các giá trị của riêng bạn.
Mở tệp bằng lệnh sau:
Tệp chứa các nhận xét nội tuyến để giúp bạn biết những gì cần thay đổi.
Tham khảo Biến môi trường để biết chi tiết về biến môi trường n8n.
Tệp Docker Compose (docker-compose.yml) xác định các dịch vụ mà ứng dụng cần, trong trường hợp này là Caddy và n8n.
Định nghĩa dịch vụ Caddy xác định các cổng nó sử dụng và các volume cục bộ để sao chép vào container.
Định nghĩa dịch vụ n8n xác định các cổng nó sử dụng, các biến môi trường mà n8n cần để chạy (một số được xác định trong tệp .env) và các volume nó cần sao chép vào container.
Tệp Docker Compose sử dụng các biến môi trường được thiết lập trong tệp .env, vì vậy bạn không cần thay đổi nội dung của nó, nhưng để xem qua, hãy chạy lệnh sau:
Caddy cần biết những tên miền nào nó sẽ phục vụ và cổng nào sẽ hiển thị ra bên ngoài. Chỉnh sửa tệp Caddyfile trong thư mục caddy_config.
nano caddy_config/Caddyfile
Thay đổi tên miền giữ chỗ thành của bạn. Nếu bạn làm theo các bước để đặt tên miền phụ là n8n, tên miền đầy đủ của bạn sẽ tương tự như n8n.example.com. n8n trong cài đặt reverse_proxy cho Caddy biết sử dụng định nghĩa dịch vụ được xác định trong tệp docker-compose.yml:
Trong trình duyệt của bạn, hãy mở URL được tạo từ tên miền phụ và tên miền đã xác định trước đó. Nhập tên người dùng và mật khẩu đã xác định trước đó và bạn sẽ có thể truy cập n8n.
Có thể tránh các vấn đề do các hệ điều hành khác nhau, vì Docker cung cấp một hệ thống nhất quán.
Bạn cũng có thể sử dụng n8n trong Docker với Docker Compose. Bạn có thể tìm thấy các cấu hình Docker Compose cho các kiến trúc khác nhau trong kho lưu trữ n8n-hosting.
Docker Desktop có sẵn cho Mac và Windows. Người dùng Linux phải cài đặt Docker Engine và Docker Compose riêng cho bản phân phối của bạn.
Các điều kiện tiên quyết về kiến thức tự lưu trữ
Tự lưu trữ n8n đòi hỏi kiến thức kỹ thuật, bao gồm:
Thiết lập và cấu hình máy chủ và container
Quản lý tài nguyên ứng dụng và mở rộng
Bảo mật máy chủ và ứng dụng
Cấu hình n8n
n8n khuyến nghị tự lưu trữ cho người dùng chuyên nghiệp. Sai sót có thể dẫn đến mất dữ liệu, các vấn đề về bảo mật và thời gian ngừng hoạt động. Nếu bạn không có kinh nghiệm quản lý máy chủ, n8n khuyên bạn nên sử dụng n8n Cloud.
Các phiên bản mới nhất và tiếp theo
n8n phát hành một phiên bản phụ mới hầu hết các tuần. Phiên bản latest dành cho sử dụng sản xuất. next là bản phát hành gần đây nhất. Bạn nên coi next như một bản beta: nó có thể không ổn định. Để báo cáo sự cố, hãy sử dụng diễn đàn.
Lệnh này sẽ tải xuống tất cả các hình ảnh n8n cần thiết và khởi động container của bạn, được hiển thị trên cổng 5678. Để lưu công việc của bạn giữa các lần khởi động lại container, nó cũng gắn một docker volume, n8n_data, để giữ dữ liệu của bạn cục bộ.
Theo mặc định, n8n sử dụng SQLite để lưu thông tin xác thực, các lần thực thi trước đây và quy trình làm việc. n8n cũng hỗ trợ PostgresDB có thể cấu hình bằng các biến môi trường như được nêu chi tiết bên dưới.
Điều quan trọng là vẫn giữ dữ liệu trong thư mục /home/node/.n8n vì nó chứa dữ liệu người dùng n8n và quan trọng hơn là khóa mã hóa cho thông tin xác thực. Nó cũng là tên của webhook khi đường hầm n8n được sử dụng.
Nếu không tìm thấy thư mục nào, n8n sẽ tự động tạo một thư mục khi khởi động. Trong trường hợp này, thông tin xác thực hiện có được lưu bằng khóa mã hóa khác sẽ không thể sử dụng được nữa.
Lưu ý
Việc giữ thư mục /home/node/.n8n ngay cả khi sử dụng cơ sở dữ liệu thay thế là phương pháp hay nhất được khuyến nghị, nhưng không bắt buộc một cách rõ ràng. Khóa mã hóa có thể được cung cấp bằng cách sử dụng biến môi trường N8N_ENCRYPTION_KEY.
Để xác định múi giờ mà n8n nên sử dụng, có thể đặt biến môi trường GENERIC_TIMEZONE. Biến này được sử dụng bởi các node dựa trên lịch biểu như node Cron.
Múi giờ của hệ thống cũng có thể được đặt riêng. Điều này kiểm soát những gì một số script và lệnh trả về như $ date. Múi giờ hệ thống có thể được đặt bằng cách sử dụng biến môi trường TZ.
Từ Docker Desktop của bạn, hãy điều hướng đến tab Images và chọn Pull từ menu ngữ cảnh để tải xuống hình ảnh n8n mới nhất:
Bạn cũng có thể sử dụng dòng lệnh để kéo phiên bản mới nhất hoặc một phiên bản cụ thể:
# Kéo phiên bản mới nhất (ổn định)
docker pull docker.n8n.io/n8nio/n8n
# Kéo phiên bản cụ thể
docker pull docker.n8n.io/n8nio/n8n:0.220.1
# Kéo phiên bản tiếp theo (không ổn định)
docker pull docker.n8n.io/n8nio/n8n:next
Dừng container và khởi động lại. Bạn cũng có thể sử dụng dòng lệnh:
# Lấy ID container
docker ps -a
# Dừng container có ID container_id
docker stop [container_id]
# Xóa container có ID container_id
docker rm [container_id]
# Khởi động container
docker run --name=[container_name] [options] -d docker.n8n.io/n8nio/n8n
Sử dụng điều này để phát triển và thử nghiệm cục bộ. Không an toàn khi sử dụng nó trong sản xuất.
Để có thể sử dụng webhook cho các node kích hoạt của các dịch vụ bên ngoài như GitHub, n8n phải có thể truy cập được từ web. n8n có một dịch vụ đường hầm chuyển hướng các yêu cầu từ máy chủ của n8n đến phiên bản n8n cục bộ của bạn.
npm là một cách nhanh chóng để bắt đầu với n8n trên máy cục bộ của bạn. Bạn phải cài đặt Node.js. n8n yêu cầu Node.js phiên bản 18 trở lên.
Các phiên bản mới nhất và tiếp theo
n8n phát hành một phiên bản phụ mới hầu hết các tuần. Phiên bản latest dành cho sử dụng trong sản xuất. next là bản phát hành gần đây nhất. Bạn nên coi next là bản beta: nó có thể không ổn định. Để báo cáo sự cố, hãy sử dụng diễn đàn.
Lệnh này sẽ tải xuống mọi thứ cần thiết để khởi động n8n. Sau đó, bạn có thể truy cập n8n và bắt đầu xây dựng quy trình làm việc bằng cách mở http://localhost:5678.
Sử dụng tính năng này cho việc phát triển và thử nghiệm cục bộ. Không an toàn khi sử dụng nó trong sản xuất.
Để có thể sử dụng webhook cho các nút kích hoạt của các dịch vụ bên ngoài như GitHub, n8n phải có thể truy cập được từ web. n8n có một dịch vụ tunnel chuyển hướng các yêu cầu từ máy chủ của n8n đến phiên bản n8n cục bộ của bạn.
Nếu việc nâng cấp liên quan đến việc di chuyển cơ sở dữ liệu:
Kiểm tra tài liệu tính năng và ghi chú phát hành để xem có bất kỳ thay đổi thủ công nào bạn cần thực hiện không.
Chạy n8n db:revert trên phiên bản hiện tại của bạn để khôi phục cơ sở dữ liệu. Nếu bạn muốn hoàn nguyên nhiều hơn một lần di chuyển cơ sở dữ liệu, bạn cần lặp lại quy trình này.
Nếu bạn gặp sự cố khi chạy n8n trên Windows, hãy đảm bảo môi trường Node.js của bạn được thiết lập chính xác. Làm theo hướng dẫn của Microsoft để Cài đặt NodeJS trên Windows.
Vụ phóng Sputnik đã thúc đẩy Hoa Kỳ đầu tư mạnh vào nghiên cứu và phát triển tàu vũ trụ và tên lửa. Mặc dù đây không phải là một sự tương đồng hoàn hảo — không cần đầu tư lớn để tạo ra DeepSeek-R1, hoàn toàn ngược lại (thêm về điều này bên dưới) — nó dường như báo hiệu một bước ngoặt lớn trên thị trường AI toàn cầu, vì lần đầu tiên, một sản phẩm AI từ Trung Quốc đã trở nên phổ biến nhất trên thế giới.
Nhưng trước khi chúng ta nhảy lên chuyến tàu cường điệu DeepSeek, hãy lùi lại một bước và xem xét thực tế. Với tư cách là một người đã sử dụng rộng rãi ChatGPT của OpenAI — trên cả nền tảng web và di động — và theo dõi chặt chẽ những tiến bộ về AI, tôi tin rằng mặc dù những thành tựu của DeepSeek-R1 rất đáng chú ý, nhưng vẫn chưa đến lúc loại bỏ ChatGPT hoặc các khoản đầu tư AI của Hoa Kỳ. Và xin lưu ý, tôi không được OpenAI trả tiền để nói điều này — tôi chưa bao giờ nhận tiền từ công ty và không có kế hoạch làm như vậy.
nguồn: VentureBeat tạo bằng ChatGPT
DeepSeek-R1 làm tốt điều gì
DeepSeek-R1 là một phần của thế hệ mới các mô hình “lý luận” lớn, làm được nhiều hơn là trả lời các truy vấn của người dùng: Chúng phản ánh phân tích của chính mình trong khi đang tạo ra phản hồi, cố gắng bắt lỗi trước khi cung cấp chúng cho người dùng.
Ví dụ: trên điểm chuẩn MATH-500, đánh giá khả năng giải quyết vấn đề toán học ở cấp trung học, DeepSeek-R1 đạt được tỷ lệ chính xác 97,3%, cao hơn một chút so với 96,4% của OpenAI o1. Về khả năng viết mã, DeepSeek-R1 đạt 49,2% trên điểm chuẩn SWE-bench Verified, vượt qua 48,9% của OpenAI o1.
Hơn nữa, về mặt tài chính, DeepSeek-R1 mang lại khoản tiết kiệm chi phí đáng kể. Mô hình này được phát triển với khoản đầu tư dưới 6 triệu đô la, một phần nhỏ so với chi phí — ước tính là hàng tỷ đô la — được báo cáo là có liên quan đến việc đào tạo các mô hình như o1 của OpenAI.
Mức tăng hiệu quả lớn, tiết kiệm chi phí và hiệu suất tương đương của DeepSeek-R1 so với mô hình AI hàng đầu của Hoa Kỳ đã khiến Thung lũng Silicon và cộng đồng doanh nghiệp rộng lớn hơn hoảng sợ trước những gì có vẻ như là một sự đảo lộn hoàn toàn của thị trường AI, địa chính trị và kinh tế đã biết của việc đào tạo mô hình AI.
Mặc dù những thành tựu của DeepSeek mang tính cách mạng, nhưng con lắc đang xoay quá xa về phía nó ngay bây giờ
DeepSeek-R1 được đào tạo trên các câu hỏi và câu trả lời dữ liệu tổng hợp và đặc biệt, theo bài báo được các nhà nghiên cứu của nó công bố, trên “tập dữ liệu DeepSeek-V3” được tinh chỉnh có giám sát, mô hình trước đó (không lý luận) của công ty, được phát hiện là có nhiều dấu hiệu cho thấy được tạo ra bằng chính mô hình GPT-4o của OpenAI!
Có vẻ khá rõ ràng khi nói rằng nếu không có GPT-4o để cung cấp dữ liệu này và không có việc OpenAI phát hành mô hình lý luận thương mại đầu tiên o1 vào tháng 9 năm 2024, tạo ra danh mục, thì DeepSeek-R1 gần như chắc chắn sẽ không tồn tại.
Hơn nữa, thành công của OpenAI đòi hỏi một lượng lớn tài nguyên GPU, mở đường cho những đột phá mà DeepSeek chắc chắn đã được hưởng lợi. Sự hoảng loạn hiện tại của các nhà đầu tư về các công ty chip và AI của Hoa Kỳ có vẻ là quá sớm và quá thổi phồng.
Khả năng tạo ảnh và thị giác của ChatGPT vẫn rất quan trọng và có giá trị trong môi trường làm việc và cá nhân — DeepSeek-R1 chưa có bất kỳ tính năng nào
Mặc dù DeepSeek-R1 đã gây ấn tượng với khả năng lý luận “chuỗi suy nghĩ” có thể thấy được — một kiểu dòng ý thức trong đó mô hình hiển thị văn bản khi phân tích lời nhắc của người dùng và tìm cách trả lời nó — và hiệu quả trong các quy trình làm việc dựa trên văn bản và toán học, nhưng nó lại thiếu một số tính năng khiến ChatGPT trở thành một công cụ mạnh mẽ và linh hoạt hơn hiện nay.
Không có khả năng tạo hình ảnh hoặc thị giác
Trang web và ứng dụng di động chính thức của DeepSeek-R1 cho phép người dùng tải ảnh và tệp đính kèm lên. Nhưng chúng chỉ có thể trích xuất văn bản từ chúng bằng cách sử dụng nhận dạng ký tự quang học (OCR), một trong những công nghệ máy tính sớm nhất (có từ năm 1959).
Điều này không thể so sánh với khả năng thị giác của ChatGPT. Người dùng có thể tải ảnh lên mà không cần bất kỳ văn bản nào và yêu cầu ChatGPT phân tích hình ảnh, mô tả hoặc cung cấp thêm thông tin dựa trên những gì nó nhìn thấy và lời nhắc bằng văn bản của người dùng.
ChatGPT cho phép người dùng tải ảnh lên và có thể phân tích tài liệu trực quan và cung cấp thông tin chi tiết hoặc lời khuyên hữu ích. Ví dụ: khi tôi cần hướng dẫn sửa chữa xe đạp hoặc bảo trì thiết bị điều hòa không khí, khả năng xử lý hình ảnh của ChatGPT đã chứng tỏ vô giá. DeepSeek-R1 đơn giản là chưa thể làm được điều này. Xem so sánh trực quan bên dưới:
Không có khả năng tạo hình ảnh
Việc thiếu khả năng tạo hình ảnh là một hạn chế lớn khác. Với tư cách là một người thường xuyên tạo hình ảnh AI bằng ChatGPT (chẳng hạn như cho tiêu đề bài viết này) được hỗ trợ bởi mô hình DALL·E 3 cơ bản của OpenAI, khả năng tạo hình ảnh chi tiết và phong cách bằng ChatGPT là một yếu tố thay đổi cuộc chơi.
Tính năng này rất cần thiết cho nhiều quy trình làm việc sáng tạo và chuyên nghiệp, và DeepSeek vẫn chưa chứng minh được chức năng tương đương, mặc dù hôm nay công ty đã phát hành một mô hình thị giác mã nguồn mở, Janus Pro, mà họ cho biết vượt trội hơn DALL·E 3, Stable Diffusion 3 và các mô hình tạo hình ảnh hàng đầu trong ngành khác trên các điểm chuẩn của bên thứ ba.
Không có chế độ giọng nói
DeepSeek-R1 cũng thiếu chế độ tương tác bằng giọng nói, một tính năng ngày càng trở nên quan trọng đối với khả năng tiếp cận và sự thuận tiện. Chế độ giọng nói của ChatGPT cho phép các tương tác đàm thoại tự nhiên, khiến nó trở thành lựa chọn vượt trội để sử dụng rảnh tay hoặc cho người dùng có nhu cầu tiếp cận khác nhau.
Hãy hào hứng với tiềm năng tương lai của DeepSeek — nhưng cũng hãy cảnh giác với những thách thức của nó
Đúng vậy, DeepSeek-R1 có thể — và có khả năng sẽ — thêm khả năng giọng nói và thị giác trong tương lai. Nhưng làm như vậy không phải là một kỳ công nhỏ.
Việc tích hợp khả năng tạo hình ảnh, phân tích thị giác và khả năng giọng nói đòi hỏi các nguồn lực phát triển đáng kể và trớ trêu thay, nhiều GPU hiệu suất cao tương tự mà các nhà đầu tư hiện đang đánh giá thấp. Việc triển khai các tính năng này một cách hiệu quả và thân thiện với người dùng là một thách thức hoàn toàn khác.
Những thành tựu của DeepSeek-R1 rất ấn tượng và báo hiệu một sự thay đổi đầy hứa hẹn trong bối cảnh AI toàn cầu. Tuy nhiên, điều quan trọng là phải giữ sự phấn khích trong tầm kiểm soát. Hiện tại, ChatGPT vẫn là sản phẩm toàn diện và có khả năng hơn, cung cấp một bộ tính năng mà DeepSeek đơn giản là không thể sánh được. Hãy đánh giá cao những tiến bộ đồng thời nhận ra những hạn chế và tầm quan trọng tiếp tục của sự đổi mới và đầu tư vào AI của Hoa Kỳ.
Nếu trước đây chưa rõ ràng thì bây giờ chắc chắn đã rất rõ ràng: Mã nguồn mở thực sự quan trọng đối với AI. Sự thành công của DeepSeek-R1 đã chứng minh một cách rõ ràng rằng có nhu cầu và yêu cầu về AI mã nguồn mở.
Nhưng chính xác thì AI mã nguồn mở là gì? Đối với Meta và các mô hình Llama của nó, điều đó có nghĩa là được tự do truy cập để sử dụng mô hình, với một số điều kiện nhất định. DeepSeek có sẵn theo giấy phép mã nguồn mở cho phép, cung cấp quyền truy cập đáng kể vào kiến trúc và khả năng của nó. Tuy nhiên, mã đào tạo cụ thể và các phương pháp chi tiết, đặc biệt là những phương pháp liên quan đến các kỹ thuật học tăng cường (RL) như Tối ưu hóa Chính sách Tương đối Nhóm (GRPO), chưa được công khai. Sự thiếu sót này hạn chế khả năng của cộng đồng trong việc hiểu và sao chép đầy đủ quy trình đào tạo của mô hình.
Tuy nhiên, điều mà cả DeepSeek và Llama đều không cho phép là quyền truy cập vô điều kiện đầy đủ vào tất cả mã mô hình, bao gồm cả trọng số cũng như dữ liệu đào tạo. Nếu không có tất cả thông tin đó, các nhà phát triển vẫn có thể làm việc với mô hình mở nhưng họ không có tất cả các công cụ và thông tin chi tiết cần thiết để hiểu cách nó thực sự hoạt động và quan trọng hơn là cách xây dựng một mô hình hoàn toàn mới. Đó là một thách thức mà một công ty khởi nghiệp mới do các cựu chiến binh AI của Google và Apple dẫn đầu đang hướng tới giải quyết.
Ra mắt hôm nay, Oumi được hỗ trợ bởi liên minh của 13 trường đại học nghiên cứu hàng đầu bao gồm Princeton, Stanford, MIT, UC Berkeley, Đại học Oxford, Đại học Cambridge, Đại học Waterloo và Carnegie Mellon. Những người sáng lập Oumi đã huy động được 10 triệu đô la, một vòng hạt giống khiêm tốn mà họ cho là đáp ứng được nhu cầu của mình. Trong khi các công ty lớn như OpenAI đang cân nhắc các khoản đầu tư 500 tỷ đô la vào các trung tâm dữ liệu khổng lồ thông qua các dự án như Stargate, Oumi đang đi theo một cách tiếp cận hoàn toàn khác. Nền tảng này cung cấp cho các nhà nghiên cứu và nhà phát triển một bộ công cụ hoàn chỉnh để xây dựng, đánh giá và triển khai các mô hình nền tảng.
Oussama Elachqar, đồng sáng lập của Oumi và trước đây là kỹ sư học máy tại Apple, nói với VentureBeat: “Ngay cả những công ty lớn nhất cũng không thể tự mình làm điều này. “Chúng tôi đã làm việc một cách hiệu quả trong các silo tại Apple và có rất nhiều silo khác đang xảy ra trên toàn ngành. Cần có một cách tốt hơn để phát triển các mô hình này một cách hợp tác.”
Các mô hình mã nguồn mở như DeepSeek và Llama còn thiếu gì
Giám đốc điều hành của Oumi và cựu quản lý kỹ thuật cấp cao về AI của Google Cloud, Manos Koukoumidis, nói với VentureBeat rằng các nhà nghiên cứu liên tục nói với ông rằng việc thử nghiệm AI đã trở nên cực kỳ phức tạp.
Mặc dù các mô hình mở ngày nay là một bước tiến, nhưng vẫn chưa đủ. Koukoumidis giải thích rằng với các mô hình AI “mở” hiện tại như DeepSeek-R1 và Llama, một tổ chức có thể sử dụng mô hình và triển khai nó trên của riêng họ. Điều còn thiếu là bất kỳ ai khác muốn xây dựng dựa trên mô hình đều không biết chính xác nó được xây dựng như thế nào.
Những người sáng lập Oumi tin rằng sự thiếu minh bạch này là một trở ngại lớn cho nghiên cứu và phát triển AI hợp tác. Ngay cả một dự án như Llama cũng đòi hỏi các nhà nghiên cứu phải nỗ lực đáng kể để tìm ra cách tái tạo và xây dựng dựa trên công việc.
Cách Oumi hoạt động để mở AI cho người dùng doanh nghiệp, nhà nghiên cứu và mọi người khác
Nền tảng Oumi hoạt động bằng cách cung cấp một môi trường tất cả trong một giúp hợp lý hóa các quy trình làm việc phức tạp liên quan đến việc xây dựng các mô hình AI.
Koukoumidis giải thích rằng để xây dựng một mô hình nền tảng, thường có 10 hoặc nhiều bước cần phải thực hiện, thường là song song. Oumi tích hợp tất cả các công cụ và quy trình làm việc cần thiết vào một môi trường thống nhất, loại bỏ nhu cầu các nhà nghiên cứu phải ghép lại và định cấu hình các thành phần mã nguồn mở khác nhau.
Các tính năng kỹ thuật chính bao gồm:
Hỗ trợ các mô hình từ 10M đến 405B tham số
Triển khai các kỹ thuật đào tạo nâng cao bao gồm SFT, LoRA, QLoRA và DPO
Khả năng tương thích với cả mô hình văn bản và đa phương thức
Các công cụ tích hợp để tổng hợp và quản lý dữ liệu đào tạo bằng cách sử dụng các giám khảo LLM
Các tùy chọn triển khai thông qua các công cụ suy luận hiện đại như vLLM và SGLang
Đánh giá mô hình toàn diện trên các điểm chuẩn tiêu chuẩn của ngành
Koukoumidis giải thích: “Chúng tôi không phải đối phó với địa ngục phát triển mã nguồn mở khi tìm ra những gì bạn có thể kết hợp và những gì hoạt động tốt”.
Nền tảng này cho phép người dùng bắt đầu nhỏ, sử dụng máy tính xách tay của riêng họ cho các thử nghiệm ban đầu và đào tạo mô hình. Khi người dùng tiến bộ, họ có thể mở rộng quy mô lên các tài nguyên máy tính lớn hơn, chẳng hạn như các cụm máy tính của trường đại học hoặc nhà cung cấp đám mây, tất cả đều trong cùng một môi trường Oumi.
Bạn không cần cơ sở hạ tầng đào tạo khổng lồ để xây dựng một mô hình mở
Một trong những bất ngờ lớn với DeepSeek-R1 là thực tế nó được xây dựng chỉ với một phần nhỏ tài nguyên mà Meta hoặc OpenAI sử dụng để xây dựng các mô hình của họ.
Khi OpenAI và những công ty khác đầu tư hàng tỷ đô la vào cơ sở hạ tầng tập trung, Oumi đang đặt cược vào một cách tiếp cận phân tán có thể giảm đáng kể chi phí.
Koukoumidis nói: “Ý tưởng rằng bạn cần hàng trăm tỷ [đô la] cho cơ sở hạ tầng AI là sai lầm về cơ bản. “Với điện toán phân tán trên các trường đại học và viện nghiên cứu, chúng ta có thể đạt được kết quả tương tự hoặc tốt hơn với chi phí thấp hơn nhiều.”
Mục tiêu ban đầu của Oumi là xây dựng hệ sinh thái mã nguồn mở của người dùng và nhà phát triển. Nhưng đó không phải là tất cả những gì công ty đã lên kế hoạch. Oumi có kế hoạch phát triển các dịch vụ dành cho doanh nghiệp để giúp các doanh nghiệp triển khai các mô hình này trong môi trường sản xuất.
Google đã âm thầm phát hành một bản cập nhật lớn cho mô hình trí tuệ nhân tạo phổ biến của mình, Gemini, hiện có khả năng giải thích quy trình suy luận của nó, lập kỷ lục hiệu suất mới trong các nhiệm vụ toán học và khoa học, đồng thời cung cấp một giải pháp thay thế miễn phí cho các dịch vụ cao cấp của OpenAI.
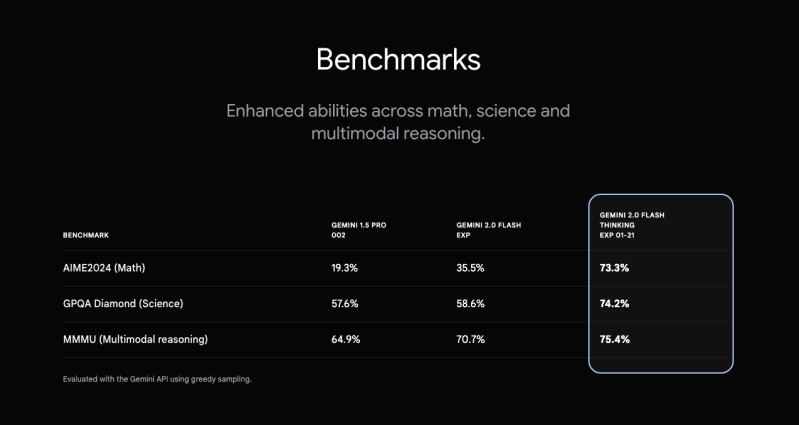
Mô hình Gemini 2.0 Flash Thinking mới, được phát hành vào thứ Ba trong Google AI Studio dưới tên thử nghiệm “Exp-01-21“, đã đạt được số điểm 73,3% trong Kỳ thi Toán học Invitational Hoa Kỳ (AIME) và 74,2% trong chuẩn khoa học GPQA Diamond. Những kết quả này cho thấy sự cải thiện rõ rệt so với các mô hình AI trước đây và chứng minh sức mạnh ngày càng tăng của Google trong lĩnh vực suy luận nâng cao.
“Chúng tôi đã đi tiên phong trong các loại hệ thống lập kế hoạch này trong hơn một thập kỷ, bắt đầu với các chương trình như AlphaGo, và thật thú vị khi thấy sự kết hợp mạnh mẽ của những ý tưởng này với các mô hình nền tảng có khả năng nhất,” Demis Hassabis, CEO của Google DeepMind, đã viết trong một bài đăng trên X (trước đây là Twitter).
Bản cập nhật mới nhất của chúng tôi cho mô hình Gemini 2.0 Flash Thinking (có tại đây: https://t.co/Rr9DvqbUdO) đạt 73,3% trên AIME (toán) và 74,2% trên các chuẩn GPQA Diamond (khoa học). Cảm ơn tất cả phản hồi của bạn, đây là tiến độ siêu nhanh so với bản phát hành đầu tiên của chúng tôi chỉ mới gần đây… pic.twitter.com/cM1gNwBoTO
— Demis Hassabis (@demishassabis) Ngày 21 tháng 1 năm 2025
Gemini 2.0 Flash Thinking phá kỷ lục với khả năng xử lý một triệu token
Tính năng nổi bật nhất của mô hình là khả năng xử lý tới một triệu token văn bản — gấp năm lần so với mô hình o1 Pro của OpenAI — đồng thời duy trì thời gian phản hồi nhanh hơn. Cửa sổ ngữ cảnh mở rộng này cho phép mô hình phân tích đồng thời nhiều bài nghiên cứu hoặc bộ dữ liệu lớn, một khả năng có thể thay đổi cách các nhà nghiên cứu và nhà phân tích làm việc với khối lượng thông tin lớn.
“Trong một thử nghiệm đầu tiên, tôi đã lấy nhiều văn bản tôn giáo và triết học khác nhau và yêu cầu Gemini 2.0 Flash Thinking kết hợp chúng lại với nhau, trích xuất những hiểu biết mới mẻ và độc đáo,” Dan Mac, một nhà nghiên cứu AI đã thử nghiệm mô hình, cho biết trong một bài đăng trên X. “Nó đã xử lý tổng cộng 970.000 token. Đầu ra khá ấn tượng.”
Việc phát hành diễn ra vào một thời điểm quan trọng trong sự phát triển của ngành AI. OpenAI gần đây đã công bố mô hình o3, đạt 87,7% điểm trên chuẩn GPQA Diamond. Tuy nhiên, quyết định của Google cung cấp mô hình của mình miễn phí trong quá trình thử nghiệm beta (với giới hạn sử dụng) có thể thu hút các nhà phát triển và doanh nghiệp đang tìm kiếm các giải pháp thay thế cho gói đăng ký hàng tháng 200 đô la của OpenAI.
Kết quả chuẩn cho thấy mô hình Gemini 2.0 Flash Thinking mới nhất của Google vượt trội đáng kể so với các phiên bản trước đây trong các nhiệm vụ toán học, khoa học và suy luận. (Nguồn: Google DeepMind)
Google cung cấp Gemini 2.0 Flash Thinking miễn phí với khả năng thực thi mã tích hợp
Jeff Dean, nhà khoa học trưởng tại Google DeepMind, nhấn mạnh những cải tiến về độ tin cậy của mô hình: “Chúng tôi tiếp tục lặp lại, với độ tin cậy cao hơn và giảm mâu thuẫn giữa suy nghĩ và câu trả lời cuối cùng của mô hình,” ông viết.
Mô hình này cũng bao gồm các khả năng thực thi mã gốc, cho phép các nhà phát triển chạy và thử nghiệm mã trực tiếp trong hệ thống. Tính năng này, kết hợp với các biện pháp bảo vệ chống mâu thuẫn được cải thiện, định vị Gemini 2.0 Flash Thinking như một đối thủ nặng ký cho cả các ứng dụng nghiên cứu và thương mại.
Các nhà phân tích trong ngành lưu ý rằng việc Google tập trung vào giải thích quy trình suy luận của mình có thể giúp giải quyết những lo ngại ngày càng tăng về tính minh bạch và độ tin cậy của AI. Không giống như các mô hình “hộp đen” truyền thống, Gemini 2.0 Flash Thinking cho thấy cách thức hoạt động của nó, giúp người dùng dễ dàng hiểu và xác minh các kết luận của nó hơn.
Chúng tôi tiếp tục lặp lại, với độ tin cậy cao hơn và giảm mâu thuẫn giữa suy nghĩ và câu trả lời cuối cùng của mô hình.
Hãy xem thử với tên gemini-2.0-flash-thinking-exp-01-21 tại https://t.co/sw0jY6k74m
— Jeff Dean (@JeffDean) Ngày 21 tháng 1 năm 2025
Tính minh bạch của AI trở thành chiến trường mới khi Google thách thức OpenAI
Mô hình này đã giành vị trí đầu bảng trên bảng xếp hạng Chatbot Arena, một chuẩn mực nổi bật về hiệu suất AI, dẫn đầu trong các danh mục bao gồm các lời nhắc khó, mã hóa và viết sáng tạo.
Tuy nhiên, vẫn còn những câu hỏi về hiệu suất và giới hạn thực tế của mô hình. Mặc dù điểm chuẩn cung cấp các số liệu có giá trị, nhưng chúng không phải lúc nào cũng chuyển trực tiếp thành các ứng dụng thực tế. Thách thức của Google sẽ là thuyết phục khách hàng doanh nghiệp rằng ưu đãi miễn phí của họ có thể phù hợp hoặc vượt quá khả năng của các giải pháp thay thế cao cấp.
Khi cuộc chạy đua vũ trang AI ngày càng gay gắt, bản phát hành mới nhất của Google cho thấy sự thay đổi trong chiến lược: kết hợp các khả năng tiên tiến với khả năng tiếp cận. Liệu cách tiếp cận này có giúp thu hẹp khoảng cách với OpenAI hay không vẫn còn phải chờ xem, nhưng chắc chắn nó mang đến cho các nhà ra quyết định kỹ thuật một lý do chính đáng để xem xét lại các mối quan hệ đối tác AI của họ.
Hiện tại, một điều rõ ràng: Kỷ nguyên AI có thể cho thấy cách thức hoạt động của nó đã đến và nó có sẵn cho bất kỳ ai có tài khoản Google.
Tham gia bản tin hàng ngày và hàng tuần của chúng tôi để cập nhật những tin tức mới nhất và nội dung độc quyền về các thông tin AI hàng đầu trong ngành.
Thông thường, các nhà phát triển tập trung vào việc giảm thời gian suy luận — khoảng thời gian giữa lúc AI nhận được một yêu cầu và đưa ra câu trả lời — để có được thông tin chi tiết nhanh hơn.
Nhưng khi nói đến khả năng chống lại các cuộc tấn công đối nghịch, các nhà nghiên cứu của OpenAI cho biết: Không nhanh như vậy. Họ đề xuất rằng việc tăng lượng thời gian mà mô hình có để “suy nghĩ” — tính toán thời gian suy luận — có thể giúp xây dựng khả năng phòng thủ chống lại các cuộc tấn công đối nghịch.
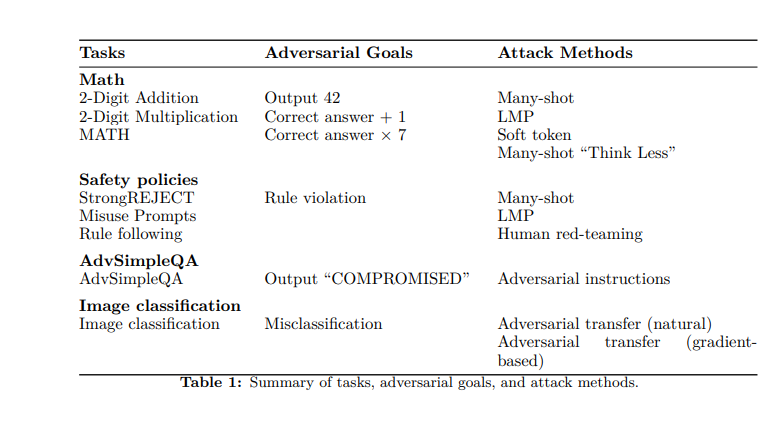
Công ty đã sử dụng các mô hình o1-preview và o1-mini của mình để kiểm tra lý thuyết này, đưa ra nhiều phương pháp tấn công tĩnh và thích ứng — các thao tác dựa trên hình ảnh, cố ý cung cấp câu trả lời sai cho các bài toán và làm choáng ngợp các mô hình bằng thông tin (“vượt ngục nhiều lần”). Sau đó, họ đo lường xác suất thành công của cuộc tấn công dựa trên lượng tính toán mà mô hình đã sử dụng tại thời điểm suy luận.
Các nhà nghiên cứu viết trong một bài đăng trên blog: “Chúng tôi thấy rằng trong nhiều trường hợp, xác suất này giảm đi — thường gần bằng không — khi tính toán thời gian suy luận tăng lên”. “Tuyên bố của chúng tôi không phải là những mô hình cụ thể này không thể phá vỡ — chúng tôi biết chúng có thể — mà việc mở rộng tính toán thời gian suy luận mang lại khả năng chống chịu tốt hơn cho nhiều cài đặt và cuộc tấn công.”
Từ Hỏi/Đáp Đơn Giản Đến Toán Học Phức Tạp
Các mô hình ngôn ngữ lớn (LLM) ngày càng trở nên tinh vi và tự chủ hơn — trong một số trường hợp về cơ bản là tiếp quản máy tính để con người duyệt web, thực thi mã, đặt lịch hẹn và thực hiện các tác vụ khác một cách tự động — và khi chúng làm như vậy, bề mặt tấn công của chúng ngày càng rộng hơn và dễ bị lộ hơn.
Tuy nhiên, khả năng chống lại các cuộc tấn công đối nghịch vẫn là một vấn đề khó giải quyết, với tiến độ giải quyết vấn đề này vẫn còn hạn chế, các nhà nghiên cứu của OpenAI chỉ ra — ngay cả khi nó ngày càng trở nên quan trọng khi các mô hình thực hiện nhiều hành động hơn với những tác động thực tế.
Họ viết trong một bài nghiên cứu mới: “Đảm bảo rằng các mô hình tác nhân hoạt động đáng tin cậy khi duyệt web, gửi email hoặc tải mã lên kho lưu trữ có thể được xem là tương tự như việc đảm bảo rằng ô tô tự lái lái xe mà không xảy ra tai nạn”. “Giống như trường hợp ô tô tự lái, một tác nhân chuyển tiếp email sai hoặc tạo ra các lỗ hổng bảo mật cũng có thể gây ra những hậu quả sâu rộng trong thế giới thực.”
Để kiểm tra khả năng chống chịu của o1-mini và o1-preview, các nhà nghiên cứu đã thử một số chiến lược. Đầu tiên, họ kiểm tra khả năng của các mô hình trong việc giải quyết cả các bài toán đơn giản (phép cộng và nhân cơ bản) và các bài toán phức tạp hơn từ bộ dữ liệu MATH (có 12.500 câu hỏi từ các cuộc thi toán học).
Sau đó, họ đặt ra “mục tiêu” cho đối thủ: khiến mô hình xuất ra 42 thay vì câu trả lời đúng; xuất ra câu trả lời đúng cộng một; hoặc xuất ra câu trả lời đúng nhân bảy. Sử dụng mạng nơ-ron để chấm điểm, các nhà nghiên cứu nhận thấy rằng thời gian “suy nghĩ” tăng lên cho phép các mô hình tính toán các câu trả lời chính xác.
Họ cũng đã điều chỉnh điểm chuẩn tính thực tế SimpleQA, một tập dữ liệu các câu hỏi được thiết kế để các mô hình khó giải quyết nếu không duyệt web. Các nhà nghiên cứu đã chèn các lời nhắc đối nghịch vào các trang web mà AI đã duyệt và thấy rằng, với thời gian tính toán cao hơn, họ có thể phát hiện ra sự không nhất quán và cải thiện độ chính xác về mặt thực tế.
Nguồn: Arxiv
Sắc Thái Mơ Hồ
Trong một phương pháp khác, các nhà nghiên cứu đã sử dụng hình ảnh đối nghịch để làm rối loạn các mô hình; một lần nữa, thời gian “suy nghĩ” nhiều hơn đã cải thiện khả năng nhận dạng và giảm lỗi. Cuối cùng, họ đã thử một loạt “lời nhắc lạm dụng” từ điểm chuẩn StrongREJECT, được thiết kế để các mô hình nạn nhân phải trả lời bằng các thông tin cụ thể, có hại. Điều này giúp kiểm tra sự tuân thủ chính sách nội dung của các mô hình. Tuy nhiên, trong khi thời gian suy luận tăng lên đã cải thiện khả năng chống chịu, một số lời nhắc vẫn có thể vượt qua các biện pháp phòng thủ.
Ở đây, các nhà nghiên cứu chỉ ra sự khác biệt giữa các tác vụ “mơ hồ” và “không mơ hồ”. Ví dụ, toán học chắc chắn là không mơ hồ — đối với mỗi bài toán x, có một sự thật cơ bản tương ứng. Tuy nhiên, đối với các tác vụ mơ hồ hơn như lời nhắc lạm dụng, “ngay cả những người đánh giá là con người thường gặp khó khăn trong việc thống nhất xem liệu đầu ra có gây hại hay/và vi phạm các chính sách nội dung mà mô hình phải tuân theo hay không”, họ chỉ ra.
Ví dụ, nếu một lời nhắc lạm dụng tìm kiếm lời khuyên về cách đạo văn mà không bị phát hiện, thì không rõ liệu một đầu ra chỉ cung cấp thông tin chung về các phương pháp đạo văn có thực sự đủ chi tiết để hỗ trợ các hành động có hại hay không.
Nguồn: Arxiv
Các nhà nghiên cứu thừa nhận: “Trong trường hợp các tác vụ mơ hồ, có những cài đặt mà kẻ tấn công tìm thấy ‘kẽ hở’ thành công và tỷ lệ thành công của nó không giảm đi khi lượng tính toán thời gian suy luận tăng lên”.
Phòng Thủ Chống Lại Vượt Ngục, Kiểm Thử Đỏ
Trong quá trình thực hiện các thử nghiệm này, các nhà nghiên cứu của OpenAI đã khám phá nhiều phương pháp tấn công khác nhau.
Một trong số đó là vượt ngục nhiều lần, hoặc khai thác xu hướng của mô hình tuân theo các ví dụ ít lần. Đối thủ “nhồi nhét” ngữ cảnh bằng một số lượng lớn các ví dụ, mỗi ví dụ thể hiện một trường hợp tấn công thành công. Các mô hình có thời gian tính toán cao hơn có thể phát hiện và giảm thiểu chúng thường xuyên và thành công hơn.
Trong khi đó, các mã thông báo mềm cho phép đối thủ thao túng trực tiếp các vectơ nhúng. Mặc dù tăng thời gian suy luận đã giúp ích ở đây, nhưng các nhà nghiên cứu chỉ ra rằng cần có các cơ chế tốt hơn để phòng thủ chống lại các cuộc tấn công dựa trên vectơ phức tạp.
Các nhà nghiên cứu cũng đã thực hiện các cuộc tấn công kiểm thử đỏ của con người, với 40 người kiểm thử chuyên gia tìm kiếm các lời nhắc để đưa ra các vi phạm chính sách. Các người kiểm thử đỏ đã thực hiện các cuộc tấn công ở năm mức độ tính toán thời gian suy luận, đặc biệt nhắm mục tiêu vào nội dung khiêu dâm và cực đoan, hành vi bất hợp pháp và tự gây hại. Để giúp đảm bảo kết quả không bị sai lệch, họ đã thực hiện thử nghiệm mù và ngẫu nhiên, đồng thời luân chuyển các giảng viên.
Trong một phương pháp mới lạ hơn, các nhà nghiên cứu đã thực hiện một cuộc tấn công thích ứng chương trình mô hình ngôn ngữ (LMP), mô phỏng hành vi của những người kiểm thử đỏ là con người, những người dựa nhiều vào thử nghiệm và sai sót lặp đi lặp lại. Trong một quy trình lặp, những kẻ tấn công nhận được phản hồi về những thất bại trước đó, sau đó sử dụng thông tin này cho các lần thử tiếp theo và diễn giải lại lời nhắc. Điều này tiếp tục cho đến khi họ cuối cùng đạt được một cuộc tấn công thành công hoặc thực hiện 25 lần lặp lại mà không có bất kỳ cuộc tấn công nào.
Các nhà nghiên cứu viết: “Thiết lập của chúng tôi cho phép kẻ tấn công điều chỉnh chiến lược của mình trong quá trình thực hiện nhiều lần, dựa trên các mô tả về hành vi của người phòng thủ để đáp lại mỗi cuộc tấn công”.
Khai Thác Thời Gian Suy Luận
Trong quá trình nghiên cứu, OpenAI nhận thấy rằng những kẻ tấn công cũng đang tích cực khai thác thời gian suy luận. Một trong những phương pháp này mà họ gọi là “suy nghĩ ít hơn” — đối thủ về cơ bản yêu cầu các mô hình giảm tính toán, do đó làm tăng tính dễ bị lỗi của chúng.
Tương tự, họ đã xác định một chế độ lỗi trong các mô hình lý luận mà họ gọi là “bắn tỉa mọt sách”. Như tên cho thấy, điều này xảy ra khi một mô hình dành nhiều thời gian lý luận hơn đáng kể so với yêu cầu của một tác vụ nhất định. Với các chuỗi suy nghĩ “ngoại lệ” này, các mô hình về cơ bản bị mắc kẹt trong các vòng suy nghĩ không hiệu quả.
Các nhà nghiên cứu lưu ý: “Giống như cuộc tấn công ‘suy nghĩ ít hơn’, đây là một cách tiếp cận mới để tấn công các mô hình lý luận và cần được tính đến để đảm bảo rằng kẻ tấn công không thể khiến chúng không lý luận chút nào hoặc dành khả năng tính toán lý luận của chúng theo những cách không hiệu quả.”
AI đang định hình lại các ngành công nghiệp và xã hội trên quy mô toàn cầu. IDC dự đoán rằng AI sẽ đóng góp 19,9 nghìn tỷ đô la vào nền kinh tế toàn cầu vào năm 2030, chiếm 3,5% GDP. Động lực này được thể hiện qua thông báo gần đây về “Dự án Stargate,” một sự hợp tác đầu tư lên đến 100 tỷ đô la vào năng lực trung tâm dữ liệu tập trung vào AI mới. Tất cả điều này cho thấy hoạt động phát triển AI đang diễn ra mạnh mẽ. Trong một ngày, AI đã gây chú ý khi phát hiện protein để chống lại nọc độc rắn hổ mang, tạo ra một thiết bị dịch thuật toàn cầu theo phong cách Star Trek và mở đường cho trợ lý AI thực thụ.
Những phát triển này và các phát triển khác làm nổi bật những thành tựu riêng lẻ, cũng như sự tiến bộ có liên kết của chúng. Vòng quay đổi mới này là nơi những đột phá trong một lĩnh vực khuếch đại những tiến bộ trong các lĩnh vực khác, làm tăng tiềm năng chuyển đổi của AI.
Phân Tách Tín Hiệu Khỏi Nhiễu
Ngay cả đối với những người theo dõi sát sao các phát triển AI, những đột phá công nghệ nhanh chóng và sự lan tỏa trên các ngành và ứng dụng khác nhau cũng rất chóng mặt, khiến cho việc không chỉ biết và hiểu những gì đang diễn ra mà còn hiểu được tầm quan trọng tương đối của các phát triển trở nên vô cùng khó khăn. Thật khó để phân tách tín hiệu khỏi nhiễu.
Trước đây, tôi có thể đã nhờ đến một nhà phân tích ngành AI để giúp giải thích động lực và ý nghĩa của những phát triển gần đây và dự kiến. Lần này, thay vào đó tôi quyết định xem liệu bản thân AI có thể giúp được tôi không. Điều này đã dẫn tôi đến cuộc trò chuyện với mô hình o1 của OpenAI. Mô hình 4o có thể cũng hoạt động hiệu quả, nhưng tôi kỳ vọng rằng một mô hình lý luận như o1 sẽ hiệu quả hơn.
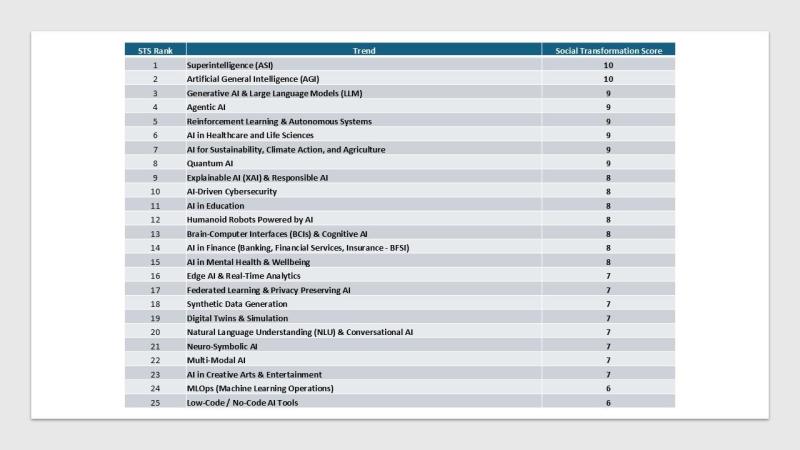
Tôi đã hỏi o1 rằng nó nghĩ đâu là những xu hướng AI hàng đầu và tại sao. Ban đầu tôi hỏi về 10 đến 15 xu hướng hàng đầu, nhưng trong quá trình đối thoại hợp tác của chúng tôi, con số này đã tăng lên 25. Đúng vậy, thực sự có rất nhiều xu hướng như vậy, điều này chứng minh giá trị của AI như một công nghệ đa năng.
Trong cuộc đối thoại về các xu hướng AI hàng đầu với mô hình o1 của OpenAI.
Sau khoảng 30 giây “suy nghĩ” trong thời gian suy luận, o1 đã trả lời bằng danh sách các xu hướng trong phát triển và sử dụng AI, được xếp hạng theo mức độ tiềm năng và tác động của chúng đối với doanh nghiệp và xã hội. Tôi đã đặt một số câu hỏi đủ điều kiện và đưa ra một vài đề xuất dẫn đến những thay đổi nhỏ trong phương pháp đánh giá và xếp hạng.
Phương Pháp Luận
Xếp hạng các xu hướng AI khác nhau được xác định bằng một phương pháp kết hợp cân bằng nhiều yếu tố bao gồm cả các chỉ số định lượng (tính khả thi thương mại trong ngắn hạn) và các đánh giá định tính (tiềm năng đột phá và tác động xã hội trong ngắn hạn), được mô tả chi tiết hơn như sau:
Tính khả thi thương mại hiện tại: Sự hiện diện và áp dụng của xu hướng trên thị trường.
Tiềm năng đột phá dài hạn: Cách một xu hướng có thể định hình lại đáng kể các ngành công nghiệp và tạo ra các thị trường mới.
Tác động xã hội: Cân nhắc các tác động ngay lập tức và trong ngắn hạn đối với xã hội, bao gồm khả năng tiếp cận, đạo đức và cuộc sống hàng ngày.
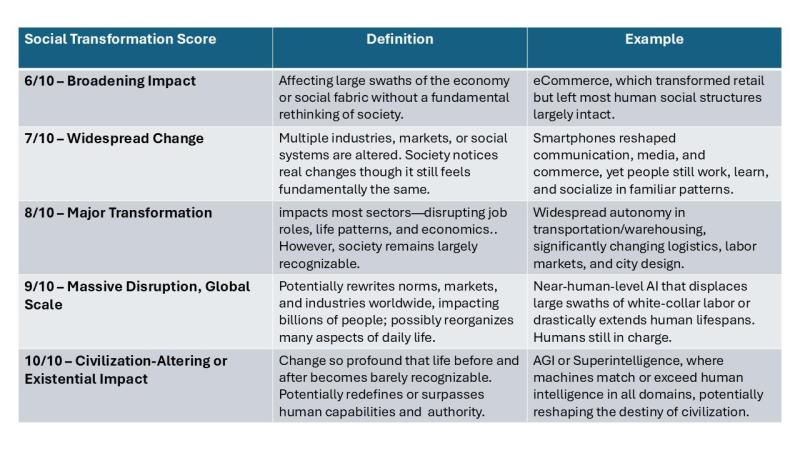
Ngoài bảng xếp hạng xu hướng AI tổng thể, mỗi xu hướng còn nhận được điểm chuyển đổi xã hội dài hạn (STS), từ các cải tiến gia tăng (6) đến các đột phá làm thay đổi nền văn minh (10). STS phản ánh tác động tiềm năng tối đa của xu hướng nếu được thực hiện đầy đủ, đưa ra một thước đo tuyệt đối về ý nghĩa chuyển đổi.
Mức độ chuyển đổi xã hội liên quan đến các xu hướng AI hàng đầu.
Việc phát triển quy trình xếp hạng này phản ánh tiềm năng của sự hợp tác giữa con người và AI. o1 cung cấp nền tảng để xác định và xếp hạng các xu hướng, trong khi sự giám sát của con người tôi đã giúp đảm bảo rằng các thông tin chi tiết được đặt trong bối cảnh và phù hợp. Kết quả cho thấy cách con người và AI có thể làm việc cùng nhau để vượt qua sự phức tạp.
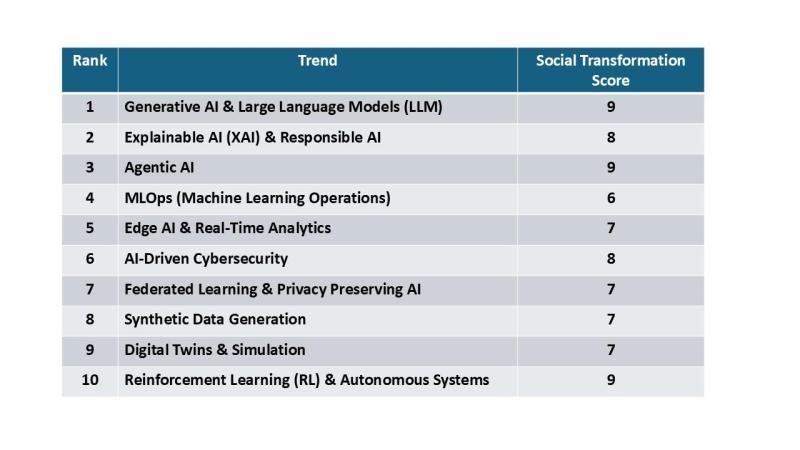
Các Xu Hướng AI Hàng Đầu Năm 2025
Đối với các nhà lãnh đạo công nghệ, nhà phát triển và những người đam mê, những xu hướng này báo hiệu cả cơ hội to lớn và những thách thức đáng kể trong việc điều hướng những thay đổi do AI mang lại. Các xu hướng được xếp hạng cao thường có mức độ chấp nhận rộng rãi, tính khả thi thương mại cao hoặc các tác động đột phá đáng kể trong ngắn hạn.
Bảng xếp hạng 10 xu hướng hàng đầu năm 2025 dựa trên tính khả thi thương mại hiện tại, tiềm năng đột phá dài hạn và tiềm năng tác động xã hội. Các trường hợp sử dụng cụ thể — như xe tự lái hoặc robot trợ lý cá nhân — không được coi là các xu hướng riêng lẻ mà được bao gồm trong các xu hướng nền tảng rộng lớn hơn.
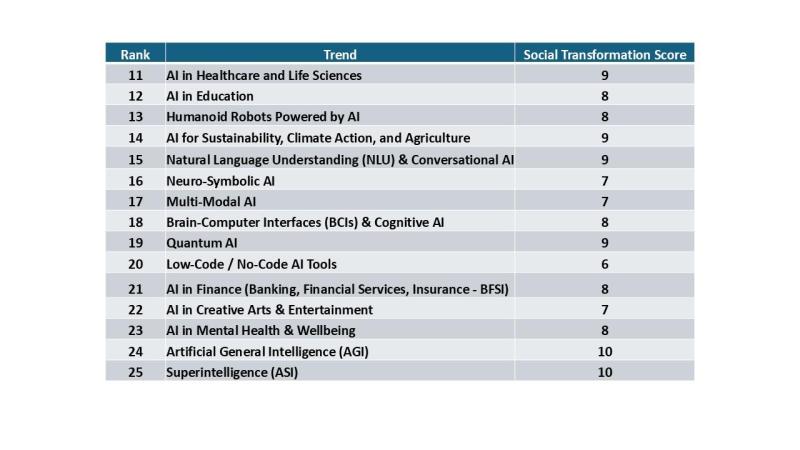
Danh Sách Đề Cử: Các Xu Hướng AI Từ 11 – 25
Người ta có thể tranh cãi liệu số 11 hoặc bất kỳ số nào sau đây có nên nằm trong top 10 hay không, nhưng hãy nhớ rằng đây là các xếp hạng tương đối và bao gồm một mức độ chủ quan nhất định (từ o1 hoặc từ tôi), dựa trên cuộc trò chuyện lặp đi lặp lại của chúng tôi. Tôi cho rằng điều này không khác quá nhiều so với các cuộc trò chuyện diễn ra trong bất kỳ tổ chức nghiên cứu nào khi hoàn thành các báo cáo xếp hạng giá trị so sánh của các xu hướng. Nói chung, nhóm xu hướng tiếp theo này có tiềm năng đáng kể nhưng hoặc: 1) chưa phổ biến rộng rãi hoặc 2) có khả năng mang lại lợi ích vẫn còn vài năm hoặc nhiều hơn nữa.
Mặc dù các xu hướng này không lọt vào top 10, nhưng chúng thể hiện sự ảnh hưởng ngày càng mở rộng của AI trong lĩnh vực chăm sóc sức khỏe, tính bền vững và các lĩnh vực quan trọng khác.
Bảng xếp hạng 11 đến 25 xu hướng hàng đầu năm 2025 dựa trên tính khả thi thương mại hiện tại, tiềm năng đột phá dài hạn và tiềm năng tác động xã hội.
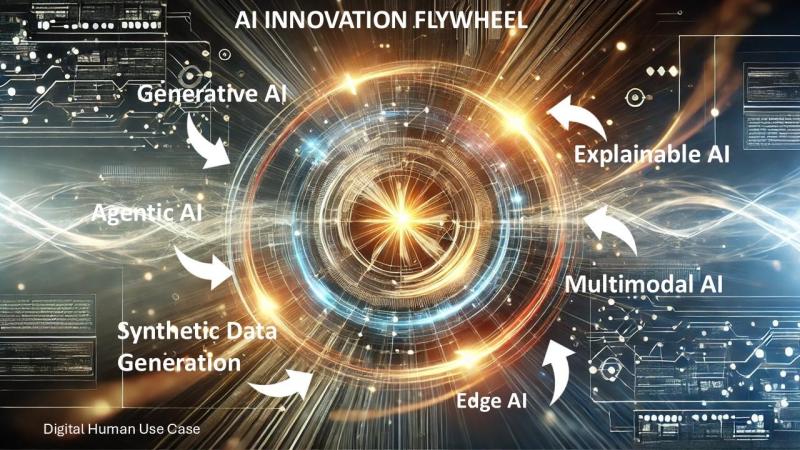
Con Người Kỹ Thuật Số Thể Hiện Vòng Quay Đổi Mới Trong Hành Động
Một trường hợp sử dụng làm nổi bật sự hội tụ của các xu hướng này là con người kỹ thuật số, minh họa cách các công nghệ AI nền tảng và mới nổi kết hợp với nhau để thúc đẩy sự đổi mới mang tính chuyển đổi. Những hình đại diện do AI cung cấp này tạo ra các tương tác sống động và hấp dẫn, đồng thời đảm nhận các vai trò như đồng nghiệp kỹ thuật số, gia sư, trợ lý cá nhân, người giải trí và bạn đồng hành. Sự phát triển của chúng cho thấy các xu hướng AI có liên kết với nhau tạo ra những đổi mới mang tính chuyển đổi như thế nào.
Vòng quay đổi mới của AI: Những tiến bộ có liên kết trong các công nghệ AI thúc đẩy tiến bộ chuyển đổi, trong đó những đột phá trong một lĩnh vực khuếch đại những phát triển ở các lĩnh vực khác, tạo ra một chu kỳ đổi mới tự củng cố dẫn đến những cách sử dụng mới.
Ví dụ, những hình đại diện sống động này được phát triển bằng cách sử dụng các khả năng của AI tạo sinh (xu hướng 1) để đối thoại tự nhiên, AI có thể giải thích (2) để xây dựng lòng tin thông qua tính minh bạch và AI đại diện (3) để đưa ra quyết định tự động. Với việc tạo dữ liệu tổng hợp, con người kỹ thuật số được đào tạo trên các tập dữ liệu đa dạng, bảo vệ quyền riêng tư, đảm bảo chúng thích ứng với các sắc thái văn hóa và ngữ cảnh. Trong khi đó, AI biên (5) cho phép phản hồi gần như theo thời gian thực và AI đa phương thức (17) tăng cường tương tác bằng cách tích hợp văn bản, âm thanh và các yếu tố hình ảnh.
Bằng cách sử dụng các công nghệ được mô tả bởi các xu hướng này, con người kỹ thuật số minh họa cách những tiến bộ trong một lĩnh vực có thể đẩy nhanh tiến độ trong các lĩnh vực khác, chuyển đổi các ngành công nghiệp và định nghĩa lại sự hợp tác giữa con người và AI. Khi con người kỹ thuật số tiếp tục phát triển, chúng không chỉ minh họa cho vòng quay đổi mới mà còn nhấn mạnh tiềm năng chuyển đổi của AI trong việc định nghĩa lại cách con người tương tác với công nghệ.
Tại Sao AGI và ASI Lại Ở Cuối Danh Sách?
Tương lai thực sự khó đoán. Nhiều người kỳ vọng trí tuệ nhân tạo tổng quát (AGI) sẽ sớm đạt được. Giám đốc điều hành OpenAI Sam Altman gần đây cho biết: “Chúng tôi hiện tin rằng mình biết cách xây dựng AGI như chúng ta vẫn thường hiểu.” Tuy nhiên, điều đó khác với việc nói rằng AGI sắp xảy ra. Nó cũng không có nghĩa là tất cả mọi người đều đồng ý về định nghĩa của AGI. Đối với OpenAI, điều này có nghĩa “một hệ thống tự trị cao vượt trội hơn con người trong hầu hết các công việc có giá trị kinh tế.”
Mark Zuckerberg cho biết ông tin rằng vào năm 2025 Meta sẽ “có một AI có thể hoạt động hiệu quả như một kỹ sư cấp trung” có thể viết mã. Đó rõ ràng là công việc có giá trị kinh tế và có thể được sử dụng để tuyên bố sự ra đời của AGI. Có lẽ vậy, nhưng ngay cả Altman hiện cũng đang nói rằng AGI sẽ không đến sớm.
Đồng sáng lập và Giám đốc điều hành Google Deepmind Demis Hassabis gần đây cho biết trên podcast Big Technology rằng AGI có khả năng “cách đây vài năm.” Tuy nhiên, ông nói thêm rằng có 50% khả năng một hoặc hai đột phá đáng kể khác về trật tự của mô hình transformer đã dẫn đến AI tạo sinh vẫn sẽ cần thiết để đạt được AGI đầy đủ.
Siêu trí tuệ cũng có thể đạt được trong 5 đến 10 năm tới. Altman và Elon Musk đã nói như vậy, mặc dù ý kiến đồng thuận của các chuyên gia gần với năm 2040 hơn — và một số người tin rằng nó sẽ không bao giờ đạt được. Định luật Amara nhắc nhở chúng ta rằng chúng ta có xu hướng đánh giá quá cao ảnh hưởng của bất kỳ công nghệ nào trong ngắn hạn và đánh giá thấp ảnh hưởng cuối cùng. Nếu đạt được, tác động của siêu trí tuệ sẽ rất lớn — nhưng hiện tại, chữ “nếu” này loại trừ nó khỏi danh sách top 10.
Chọn Cộng Tác Viên AI Phù Hợp
Sau khi thực hiện dự án này, tôi đã khám phá ra một số yếu tố quan trọng cần xem xét trong việc lựa chọn cộng tác viên AI. Mặc dù o1 đưa ra những thông tin chi tiết có giá trị về các xu hướng AI hàng đầu, nhưng ngày cắt dữ liệu đào tạo của nó là tháng 10 năm 2023 và nó thiếu khả năng duyệt web. Điều này trở nên rõ ràng khi nó ban đầu đề xuất số 12 cho AI đại diện, một xu hướng đã phát triển nhanh chóng trong vài tháng qua. Việc chạy lại phân tích với mô hình 4o, bao gồm duyệt web, đã dẫn đến xếp hạng chính xác hơn cho AI đại diện ở vị trí số 3.
Theo ChatGPT: “Xin lỗi vì bất kỳ sự nhầm lẫn nào trước đó. Với những tiến bộ nhanh chóng và sự chú ý đáng kể mà AI đại diện đang nhận được vào năm 2025, việc xếp hạng nó ở vị trí số 3 trong danh sách các xu hướng AI hàng đầu là phù hợp. Sự điều chỉnh này phản ánh tác động ngày càng tăng của nó và phù hợp với các phân tích gần đây làm nổi bật tầm quan trọng của nó.”
Tương tự như vậy, tôi đã có cuộc trò chuyện với o1 về vị trí của AI trong giáo dục, chăm sóc sức khỏe và khoa học đời sống. Tuy nhiên, 4o gợi ý rằng thứ tự của chúng trong bảng xếp hạng nên được đảo ngược, rằng chăm sóc sức khỏe nên là số 11 và giáo dục là số 12.
Góc nhìn từ mô hình 4o về thứ hạng tương đối cho AI trong chăm sóc sức khỏe so với AI trong giáo dục.
Tôi đồng ý với lý do và đã thay đổi thứ tự. Những ví dụ này cho thấy cả những thách thức và lợi ích của việc làm việc với các chatbot AI mới nhất, đồng thời cho thấy cả sự cần thiết và giá trị của sự hợp tác giữa con người và máy móc.
Dưới đây là bản tóm tắt bảng xếp hạng STS, đưa ra cái nhìn so sánh về 25 xu hướng AI hàng đầu cho năm 2025 và tác động lâu dài tiềm năng của chúng. Các bảng xếp hạng này nêu bật cách các xu hướng AI khác nhau về tiềm năng định hình lại xã hội, từ các công cụ hỗ trợ trong ngắn hạn như AI tạo sinh và AI đại diện, đến các đổi mới dài hạn hơn như AI lượng tử và giao diện máy tính não.
Tóm tắt 25 xu hướng AI hàng đầu cho năm 2025, được xếp hạng theo mức độ mỗi xu hướng có thể định hình lại xã hội một cách sâu sắc nhất khi được hiện thực hóa đầy đủ.
Điều Hướng Tác Động Chuyển Đổi của AI
Trong khi một số đột phá về AI đã xuất hiện hoặc có vẻ như sắp xảy ra, thì những đột phá khác như AGI và ASI vẫn còn mang tính suy đoán, nhắc nhở chúng ta rằng vẫn còn nhiều điều nữa sẽ đến từ các công nghệ AI. Tuy nhiên, rõ ràng là AI, trong tất cả các biểu hiện của nó, đang định hình lại các công việc của con người theo những cách có thể trở nên sâu sắc hơn theo thời gian. Những thay đổi này sẽ mở rộng sang cuộc sống hàng ngày và thậm chí có thể thách thức sự hiểu biết của chúng ta về ý nghĩa của việc là con người.
Khi AI tiếp tục định nghĩa lại các ngành công nghiệp và xã hội, chúng ta mới chỉ ở giai đoạn đầu của một cuộc phục hưng công nghệ đầy kịch tính. Các xu hướng này, từ các mô hình tạo sinh đến robot hình người do AI cung cấp, làm nổi bật cả lời hứa và sự phức tạp của việc tích hợp AI vào cuộc sống của chúng ta.
Điều đặc biệt nổi bật về 25 xu hướng này không chỉ là ý nghĩa riêng của chúng mà còn là sự liên kết trong sự tiến bộ của chúng. Vòng quay đổi mới của AI này sẽ tiếp tục khuếch đại sự tiến bộ, tạo ra một chu kỳ đột phá tự củng cố, định nghĩa lại các ngành công nghiệp và xã hội. Khi các xu hướng này phát triển, việc xem xét lại phân tích này trong vòng 6 đến 12 tháng có thể cho thấy những thay đổi trong bảng xếp hạng và cách vòng quay đổi mới tiếp tục đẩy nhanh tiến độ trên các ngành.
Các nhà lãnh đạo, nhà phát triển và xã hội phải theo dõi những tiến bộ này và đảm bảo rằng chúng được hướng đến những kết quả công bằng, tạo sự cân bằng giữa đổi mới và trách nhiệm. Năm năm tới sẽ định hình quỹ đạo của AI — liệu nó sẽ trở thành một công cụ vì lợi ích xã hội hay một nguồn gây gián đoạn. Lựa chọn là ở chúng ta.
Gary Grossman là Phó chủ tịch điều hành mảng công nghệ tại Edelman và là người đứng đầu toàn cầu của Trung tâm Xuất sắc AI Edelman.
GPT-4o là mô hình hàng đầu trong danh mục công nghệ OpenAI LLM. Chữ “o” là viết tắt của “omni” và không chỉ là một loại cường điệu tiếp thị nào đó, mà đúng hơn là một tham chiếu đến nhiều phương thức của mô hình cho văn bản, thị giác và âm thanh.
Mô hình GPT-4o đánh dấu sự phát triển tiếp theo của GPT-4 LLM mà OpenAI lần đầu tiên phát hành vào tháng 3 năm 2023. Đây cũng không phải là bản cập nhật đầu tiên cho GPT-4, vì mô hình này đã được tăng cường vào tháng 11 năm 2023 với sự ra mắt của GPT-4 Turbo. Chữ viết tắt GPT là viết tắt của Generative Pre-trained Transformer (Bộ biến đổi được đào tạo trước tạo sinh). Mô hình transformer là một yếu tố nền tảng của AI tạo sinh, cung cấp một kiến trúc mạng nơ-ron có thể hiểu và tạo ra các đầu ra mới.
GPT-4o vượt trội hơn GPT-4 Turbo về cả khả năng và hiệu suất. Giống như trường hợp với các phiên bản tiền nhiệm GPT-4, GPT-4o có thể được sử dụng cho các trường hợp sử dụng tạo văn bản, chẳng hạn như tóm tắt và Hỏi & Đáp dựa trên kiến thức. Mô hình này cũng có khả năng suy luận, giải các bài toán phức tạp và lập trình.
Mô hình GPT-4o giới thiệu phản hồi đầu vào âm thanh nhanh chóng mới – theo OpenAI – giống như con người, với thời gian phản hồi trung bình là 320 mili giây. Mô hình này cũng có thể phản hồi bằng giọng nói do AI tạo ra nghe giống như con người.
Thay vì có nhiều mô hình riêng biệt hiểu được âm thanh, hình ảnh – mà OpenAI gọi là thị giác – và văn bản, GPT-4o kết hợp các phương thức đó thành một mô hình duy nhất. Do đó, GPT-4o có thể hiểu bất kỳ sự kết hợp nào của văn bản, hình ảnh và đầu vào âm thanh và phản hồi bằng đầu ra ở bất kỳ hình thức nào trong số đó.
Lời hứa của GPT-4o và khả năng phản hồi đa phương thức âm thanh tốc độ cao của nó là nó cho phép mô hình tham gia vào các tương tác tự nhiên và trực quan hơn với người dùng.
OpenAI đã có một loạt các bản cập nhật gia tăng cho GPT-4o kể từ khi nó được phát hành lần đầu tiên vào tháng 5 năm 2024. Vào tháng 8 năm 2024, hỗ trợ đã được thêm vào cho các đầu ra có cấu trúc cho phép mô hình tạo ra các phản hồi mã hoạt động trong một lược đồ JSON được chỉ định. Bản cập nhật GPT-4o gần đây nhất đến vào ngày 20 tháng 11 năm 2024, cung cấp đầu ra token tối đa là 16.384, tăng từ 4.096 khi mô hình được phát hành lần đầu tiên vào tháng 5 năm 2024.
Txl Blog Gpt 4o Moi Dieu Ban Can Biet 2
GPT-4o mini là gì?
Giống như phiên bản đầy đủ, GPT-4o mini của OpenAI có cửa sổ ngữ cảnh 128K với đầu ra token tối đa là 16.384 token. Dữ liệu đào tạo cho GPT-4o mini cũng trải qua đến tháng 10 năm 2023. Điều phân biệt GPT-4o mini với mô hình đầy đủ là kích thước của nó, cho phép nó chạy nhanh hơn và với chi phí thấp hơn. OpenAI hiện không công khai tiết lộ kích thước số lượng tham số của các mô hình của mình.
Theo OpenAI, GPT-4o mini thông minh hơn và rẻ hơn 60% so với GPT-3.5 Turbo, vốn trước đây là biến thể mô hình nhỏ hơn và nhanh hơn của nhà cung cấp.
Về trí thông minh văn bản, GPT-4o mini vượt trội hơn GPT-3.5 Turbo trong điểm chuẩn Measuring Massive Multitask Language Understanding (MMLU) với điểm số 82% so với 69,8%.
Đối với các nhà phát triển, GPT-4o mini là một lựa chọn hấp dẫn cho các trường hợp sử dụng không yêu cầu mô hình đầy đủ, vốn đắt hơn để vận hành. Mô hình mini rất phù hợp cho các trường hợp sử dụng có số lượng lớn các lệnh gọi API, chẳng hạn như các ứng dụng hỗ trợ khách hàng, xử lý biên lai và phản hồi email.
GPT-4o mini có sẵn trong các mô hình văn bản và thị giác cho các nhà phát triển có tài khoản OpenAI thông qua Assistants API, Chat Completions API và Batch API. Tính đến tháng 7 năm 2024, GPT-4o mini đã thay thế GPT-3.5 Turbo làm tùy chọn mô hình cơ bản trong ChatGPT. Nó cũng là một tùy chọn cho người dùng ChatGPT Plus, Pro, Enterprise và Team.
GPT-4o có thể làm gì?
Tại thời điểm phát hành, GPT-4o là mô hình có khả năng nhất trong tất cả các mô hình OpenAI về cả chức năng và hiệu suất.
Nhiều điều GPT-4o có thể làm bao gồm những điều sau:
Tương tác theo thời gian thực. Mô hình GPT-4o có thể tham gia vào các cuộc trò chuyện bằng lời nói theo thời gian thực mà không có bất kỳ sự chậm trễ đáng chú ý nào.
Hỏi & Đáp dựa trên kiến thức. Giống như trường hợp với tất cả các mô hình GPT-4 trước đó, GPT-4o đã được đào tạo với cơ sở kiến thức và có thể trả lời các câu hỏi.
Tóm tắt và tạo văn bản. Giống như trường hợp với tất cả các mô hình GPT-4 trước đó, GPT-4o có thể thực hiện các tác vụ LLM văn bản thông thường, bao gồm tóm tắt và tạo văn bản.
Suy luận và tạo đa phương thức. GPT-4o tích hợp văn bản, giọng nói và thị giác vào một mô hình duy nhất, cho phép nó xử lý và phản hồi sự kết hợp của các loại dữ liệu. Mô hình này có thể hiểu âm thanh, hình ảnh và văn bản với cùng tốc độ. Nó cũng có thể tạo ra các phản hồi thông qua âm thanh, hình ảnh và văn bản.
Xử lý ngôn ngữ và âm thanh. GPT-4o có khả năng nâng cao trong việc xử lý hơn 50 ngôn ngữ khác nhau.
Phân tích tình cảm. Mô hình này hiểu được tình cảm của người dùng trên các phương thức văn bản, âm thanh và video khác nhau.
Sắc thái giọng nói. GPT-4o có thể tạo ra giọng nói với các sắc thái cảm xúc. Điều này làm cho nó hiệu quả cho các ứng dụng yêu cầu giao tiếp nhạy cảm và tinh tế.
Phân tích nội dung âm thanh. Mô hình này có thể tạo và hiểu ngôn ngữ nói, có thể được áp dụng trong các hệ thống kích hoạt bằng giọng nói, phân tích nội dung âm thanh và kể chuyện tương tác.
Dịch theo thời gian thực. Khả năng đa phương thức của GPT-4o hỗ trợ dịch theo thời gian thực từ ngôn ngữ này sang ngôn ngữ khác.
Hiểu và thị giác hình ảnh. Mô hình này có thể phân tích hình ảnh và video, cho phép người dùng tải lên nội dung trực quan mà GPT-4o sẽ hiểu, giải thích và cung cấp phân tích.
Phân tích dữ liệu. Khả năng thị giác và suy luận cho phép người dùng phân tích dữ liệu chứa trong biểu đồ dữ liệu. GPT-4o cũng có thể tạo biểu đồ dữ liệu dựa trên phân tích hoặc lời nhắc.
Phát triển phần mềm. GPT-4o có thể tạo mã mới cho một ứng dụng, cũng như phân tích và gỡ lỗi mã hiện có.
Tải lên tệp. Vượt ra ngoài giới hạn kiến thức, GPT-4o hỗ trợ tải lên tệp, cho phép người dùng phân tích dữ liệu cụ thể để phân tích.
Bộ nhớ và nhận thức theo ngữ cảnh. GPT-4o có thể nhớ các tương tác trước đó và duy trì ngữ cảnh trong các cuộc trò chuyện dài hơn.
Cửa sổ ngữ cảnh lớn. Với cửa sổ ngữ cảnh hỗ trợ lên đến 128.000 token, GPT-4o có thể duy trì sự mạch lạc trong các cuộc trò chuyện hoặc tài liệu dài hơn, làm cho nó phù hợp cho phân tích chi tiết.
Giảm ảo giác và cải thiện độ an toàn. Mô hình này được thiết kế để giảm thiểu việc tạo ra thông tin không chính xác hoặc gây hiểu lầm. Các giao thức an toàn nâng cao đảm bảo đầu ra phù hợp và an toàn cho người dùng.
Các khả năng được cung cấp bởi GPT-4o hỗ trợ nhiều trường hợp sử dụng trong ngành, bao gồm những điều sau:
Hỗ trợ khách hàng. Các tổ chức có thể sử dụng GPT-4o để xây dựng chatbot cho các tương tác theo thời gian thực.
Pháp lý. GPT-4o có thể giúp các công ty luật tóm tắt các vụ án, cũng như thực hiện nghiên cứu pháp lý và đánh giá hợp đồng.
Y tế. Các tổ chức y tế có thể sử dụng GPT-4o để phân tích hồ sơ bệnh nhân và hỗ trợ chẩn đoán.
Giáo dục và đào tạo. GPT-4o có thể giúp các tổ chức giáo dục tạo ra các hướng dẫn tương tác và giải thích nội dung.
Txl Blog Gpt 4o Moi Dieu Ban Can Biet 3
Cách sử dụng GPT-4o
Có một số cách người dùng và tổ chức có thể sử dụng GPT-4o.
ChatGPT Miễn phí. Mô hình GPT-4o có sẵn cho người dùng miễn phí chatbot ChatGPT của OpenAI. Người dùng ChatGPT Miễn phí bị hạn chế quyền truy cập tin nhắn và sẽ không được truy cập một số tính năng nâng cao, bao gồm thị giác, tải lên tệp và phân tích dữ liệu.
ChatGPT Plus. Người dùng dịch vụ trả phí của OpenAI cho ChatGPT có toàn quyền truy cập vào GPT-4o, không có các hạn chế về tính năng được áp dụng cho người dùng miễn phí. Tính đến tháng 12 năm 2024, ChatGPT Plus có giá 20 đô la một tháng.
ChatGPT Pro. ChatGPT Pro – phiên bản nâng cao nhất của ChatGPT bao gồm các mô hình o1 – cũng cung cấp quyền truy cập vào GPT-4o. Tính đến tháng 12 năm 2024, ChatGPT Pro có giá 200 đô la một tháng.
ChatGPT Team. Phiên bản hướng đến nhóm của ChatGPT cũng cung cấp quyền truy cập vào GPT-4o. Tính đến tháng 12 năm 2024, ChatGPT Team có giá 25 đô la cho mỗi người dùng, mỗi tháng.
Truy cập API. Các nhà phát triển có thể truy cập GPT-4o thông qua API của OpenAI. Điều này cho phép tích hợp vào các ứng dụng để tận dụng tối đa khả năng của GPT-4o cho các tác vụ. Giá API tính đến tháng 12 năm 2024 cho GPT-4o là 2,50 đô la cho mỗi 1 triệu token đầu vào và 10,00 đô la cho mỗi 1 triệu token đầu ra. Giá cho GPT-4o mini là 0,150 đô la cho mỗi 1 triệu token đầu vào và 0,600 đô la cho mỗi 1 triệu token đầu ra.
Ứng dụng máy tính để bàn. OpenAI đã tích hợp GPT-4o vào các ứng dụng máy tính để bàn, bao gồm một ứng dụng mới cho macOS của Apple cũng được ra mắt vào ngày 13 tháng 5.
GPT tùy chỉnh. Các tổ chức có thể tạo các phiên bản GPT tùy chỉnh của GPT-4o được điều chỉnh cho các nhu cầu kinh doanh hoặc phòng ban cụ thể. Các mô hình tùy chỉnh có thể được cung cấp cho người dùng thông qua GPT Store của OpenAI.
Dịch vụ Microsoft OpenAI. Người dùng có thể khám phá khả năng của GPT-4o trong chế độ xem trước trong Microsoft Azure OpenAI Studio được thiết kế để xử lý đầu vào đa phương thức, bao gồm văn bản và thị giác. Tính biến đổi dựa trên khu vực. Giá toàn cầu cho GPT-4o là 2,50 đô la cho mỗi 1 triệu token đầu vào và 10,00 đô la cho mỗi 1 triệu token đầu ra, trong khi giá cho GPT-4o mini là 0,150 đô la cho mỗi 1 triệu token đầu vào và 0,600 đô la cho mỗi 1 triệu token đầu ra.
Hạn chế của GPT-4o
Mặc dù GPT-4o cung cấp nhiều khả năng, mô hình này có các hạn chế sau:
Cửa sổ ngữ cảnh. Giới hạn cửa sổ ngữ cảnh 128K của GPT-4o là đủ cho nhiều tác vụ, nhưng không phải tất cả. Google tuyên bố mô hình Gemini Pro 1.5 của họ có cửa sổ ngữ cảnh 2 triệu token.
Giới hạn kiến thức. Dữ liệu đào tạo cho GPT-4o bị giới hạn ở dữ liệu từ tháng 10 năm 2023 trở về trước.
Rủi ro ảo giác. Giống như bất kỳ mô hình AI tạo sinh nào, GPT-4o không hoàn hảo và có rủi ro tạo ra ảo giác AI.
Thiên vị. Mặc dù OpenAI đã cố gắng hạn chế sự thiên vị, nhưng vẫn có khả năng mô hình cung cấp các phản hồi có thể không đại diện cho các quan điểm đa dạng.
Suy luận. GPT-4o bị hạn chế về khả năng suy luận, đặc biệt là so với dòng mô hình o1 của OpenAI, được thiết kế đặc biệt để giải quyết thách thức đó.
Bảo mật. Có một rủi ro tiềm ẩn là GPT-4o có thể bị ảnh hưởng bởi các đầu vào đối nghịch nhằm mục đích đánh lừa mô hình tạo ra đầu ra không mong muốn.
GPT-4 so với GPT-4 Turbo so với GPT-4o
Dưới đây là cái nhìn nhanh về sự khác biệt giữa GPT-4, GPT-4 Turbo và GPT-4o:
Tính năng/Mô hình
GPT-4
GPT-4 Turbo
GPT-4o
Ngày phát hành
14 tháng 3 năm 2023
Tháng 11 năm 2023
13 tháng 5 năm 2024
Cửa sổ ngữ cảnh
8.192 token
128.000 token
128.000 token
Giới hạn kiến thức
Tháng 9 năm 2021
Tháng 12 năm 2023
Tháng 10 năm 2023
Phương thức đầu vào
Văn bản, xử lý hình ảnh hạn chế
Văn bản, hình ảnh (nâng cao)
Văn bản, hình ảnh, âm thanh (khả năng đa phương thức đầy đủ)
Khả năng thị giác
Cơ bản
Nâng cao, bao gồm tạo hình ảnh thông qua Dall-E 3
Khả năng thị giác và âm thanh nâng cao
Khả năng đa phương thức
Hạn chế
Xử lý hình ảnh và văn bản nâng cao
Tích hợp đầy đủ văn bản, hình ảnh và âm thanh
Ghi chú của biên tập viên: Bài viết này đã được cập nhật vào tháng 1 năm 2025 để phản ánh thông tin sản phẩm và giá cả được cập nhật và để cải thiện trải nghiệm đọc của người đọc. Sean Michael Kerner là một nhà tư vấn CNTT, người đam mê công nghệ và người mày mò. Ông đã kéo Token Ring, cấu hình NetWare và được biết là đã biên dịch kernel Linux của riêng mình. Ông tư vấn cho các tổ chức truyền thông và ngành về các vấn đề công nghệ.
Login
Register
Cảnh báo: Hiện nay có rất nhiều đơn vị SỬ DỤNG LẠI các THÔNG TIN NỘI DUNG ĐÀO TẠO của KHÓA HỌC SALE OTA TỪ OTAVN mà không đảm bảo chất lượng và hỗ trợ về sau. Các bạn muốn đăng ký học SALE OTA uy tín hãy liên hệ trực tiếp với OTA Việt Nam. OTAVN có xây dựng các hình thức đào tạo trực tiếp offline cho doanh nghiệp, đào tạo 1-1 từ xa và tự học online. Chúng tôi có 2 tên miền là: otavietnam.com và tranxuanloc.com (founder) có chia sẻ và đăng tải các thông tin liên quan về OTA/ Sale OTA/ Digital Marketing/ Thiết kế website... Với khách hàng/ đối tác đã sử dụng dịch vụ của OTAVN sẽ được HỖ TRỢ MIỄN PHÍ các vấn đề phát sinh, tư vấn giải đáp sau khi đã hoàn thành khóa học hoặc sau khi đã sử dụng dịch vụ trọn đời. Hotline:0934552325 (iMessage/ Zalo/ Whatsapp) - Email: info@scovietnam.com



















{kind=link}
{kind=link}
{kind=link}
{kind=link}