18 Th2
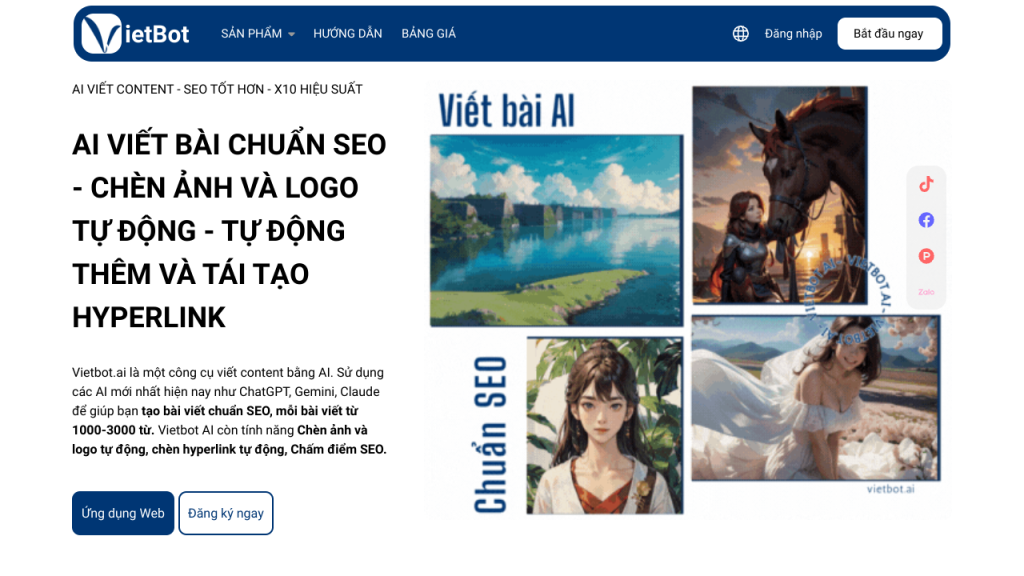
PIN AI ra mắt ứng dụng tạo AI cá nhân DeepSeek, Llama trên điện thoại
PIN AI ra mắt ứng dụng di động: Tạo mô hình AI cá nhân DeepSeek hoặc Llama trên điện thoại của bạn
Ngày 13 tháng 2 năm 2025, 09:09 AM
Tín dụng: VentureBeat được tạo bằng Midjourney
Tham gia bản tin hàng ngày và hàng tuần của chúng tôi để cập nhật những thông tin mới nhất và nội dung độc quyền về lĩnh vực AI hàng đầu. Tìm hiểu thêm
Nhờ Her và nhiều tác phẩm khoa học viễn tưởng khác, thật dễ dàng để tưởng tượng một thế giới nơi mọi người đều có trợ lý AI cá nhân – một người trợ giúp biết chúng ta là ai, nghề nghiệp, sở thích, mục tiêu, đam mê, những điều chúng ta thích và không thích… về cơ bản là điều gì khiến chúng ta “tích tắc”.
Một số công cụ AI ngày nay cung cấp một phiên bản khá sơ sài, giới hạn của chức năng này, chẳng hạn như CharacterAI và tính năng bộ nhớ mới của ChatGPT. Nhưng chúng vẫn dựa vào thông tin của bạn được chuyển đến các máy chủ của công ty bên ngoài tầm kiểm soát của bạn để phân tích và xử lý. Chúng cũng không cho phép nhiều giao dịch của bên thứ ba, nghĩa là trợ lý AI của bạn không thể mua hàng thay mặt bạn.
Đối với những người đặc biệt lo ngại về quyền riêng tư hoặc muốn một mô hình AI thực sự tự đào tạo lại để thích ứng với các tùy chọn cá nhân – tạo ra một trợ lý AI độc đáo không giống ai trên toàn thế giới – thì về cơ bản bạn phải tự mình làm.
Cho đến bây giờ: Một công ty khởi nghiệp mới PIN AI (không nên nhầm lẫn với thiết bị phần cứng bị đánh giá kém AI Pin của Humane) đã xuất hiện từ chế độ ẩn danh để ra mắt ứng dụng di động đầu tiên của mình, cho phép người dùng chọn một mô hình AI nguồn mở cơ bản chạy trực tiếp trên điện thoại thông minh của họ (hỗ trợ iOS/Apple iPhone và Google Android) và vẫn riêng tư và hoàn toàn tùy chỉnh theo sở thích của họ.
Được xây dựng với cơ sở hạ tầng phi tập trung ưu tiên quyền riêng tư, PIN AI nhằm mục đích thách thức sự thống trị của các công ty công nghệ lớn đối với dữ liệu người dùng bằng cách đảm bảo rằng AI cá nhân phục vụ các cá nhân – chứ không phải lợi ích của công ty.
Được thành lập bởi các chuyên gia về AI và blockchain từ Columbia, MIT và Stanford, PIN AI được dẫn dắt bởi Davide Crapis, Ben Wu và Bill Sun, những người có kinh nghiệm sâu sắc trong nghiên cứu AI, cơ sở hạ tầng dữ liệu quy mô lớn và bảo mật blockchain.
Công ty được hỗ trợ bởi các nhà đầu tư lớn, bao gồm a16z Crypto (CSX), Hack VC, Sequoia Capital U.S. Scout và những người tiên phong blockchain nổi tiếng như người sáng lập Near Illia Polosukhin, chủ tịch SOL Foundation Lily Liu, người sáng lập SUI Evan Cheng và đồng sáng lập Polygon Sandeep Nailwal.
AI cá nhân được hiện thực hóa
PIN AI giới thiệu một giải pháp thay thế cho các mô hình AI tập trung thu thập và kiếm tiền từ dữ liệu người dùng. Không giống như AI dựa trên đám mây do các công ty công nghệ lớn kiểm soát, AI cá nhân của PIN AI chạy cục bộ trên thiết bị của người dùng, cho phép trải nghiệm AI an toàn, tùy chỉnh mà không cần giám sát của bên thứ ba.

Trọng tâm của PIN AI là một ngân hàng dữ liệu do người dùng kiểm soát, cho phép các cá nhân lưu trữ và quản lý thông tin cá nhân của họ đồng thời cho phép các nhà phát triển truy cập vào thông tin chi tiết đa danh mục, ẩn danh – từ thói quen mua sắm đến chiến lược đầu tư. Cách tiếp cận này đảm bảo rằng các dịch vụ được hỗ trợ bởi AI có thể hưởng lợi từ dữ liệu theo ngữ cảnh chất lượng cao mà không ảnh hưởng đến quyền riêng tư của người dùng.
“Vấn đề ngày nay là tất cả những người chơi lớn đều tuyên bố họ làm AI cá nhân – Apple, Google, Meta – nhưng họ thực sự đang làm gì?” Davide Crapis, đồng sáng lập của PIN AI, cho biết trong một cuộc phỏng vấn trực tiếp với VentureBeat vào đầu tháng này. “Họ đang lấy mỏ vàng trong điện thoại của bạn và khai thác tất cả thông tin đó để tìm ra những gì cần đẩy cho bạn.”

PIN AI đã ra mắt phiên bản chỉ dành cho web vào cuối năm ngoái và đã đạt được sức hút to lớn, với hơn 2 triệu người dùng alpha thông qua Telegram và cộng đồng Discord gồm 220.000 thành viên.
Ứng dụng di động mới ra mắt tại Hoa Kỳ và nhiều khu vực cũng bao gồm các tính năng chính như:
- “Mô hình Thần thánh” (người bảo vệ dữ liệu): Giúp người dùng theo dõi mức độ hiểu biết của AI về họ, đảm bảo nó phù hợp với sở thích của họ.
- Hỏi PIN AI: Một trợ lý AI được cá nhân hóa có khả năng xử lý các tác vụ như lập kế hoạch tài chính, điều phối du lịch và đề xuất sản phẩm.
- Tích hợp nguồn mở: Người dùng có thể kết nối các ứng dụng như Gmail, nền tảng truyền thông xã hội và dịch vụ tài chính với AI cá nhân của họ, đào tạo nó để phục vụ họ tốt hơn mà không tiết lộ dữ liệu cho bên thứ ba.
“Với ứng dụng của chúng tôi, bạn có một AI cá nhân là mô hình của bạn,” Crapis nói thêm. “Bạn sở hữu các trọng số và nó hoàn toàn riêng tư, với khả năng tinh chỉnh bảo toàn quyền riêng tư.”
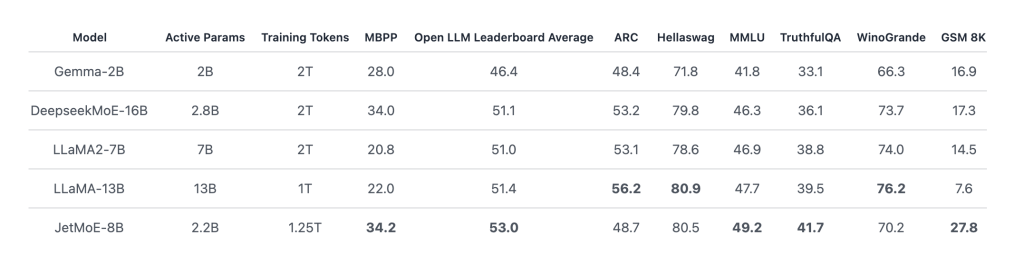
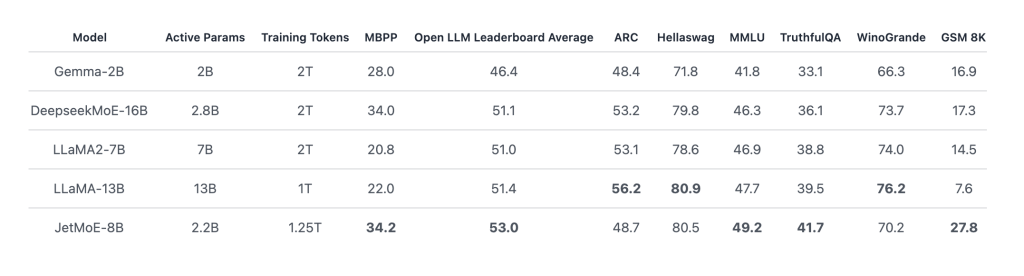
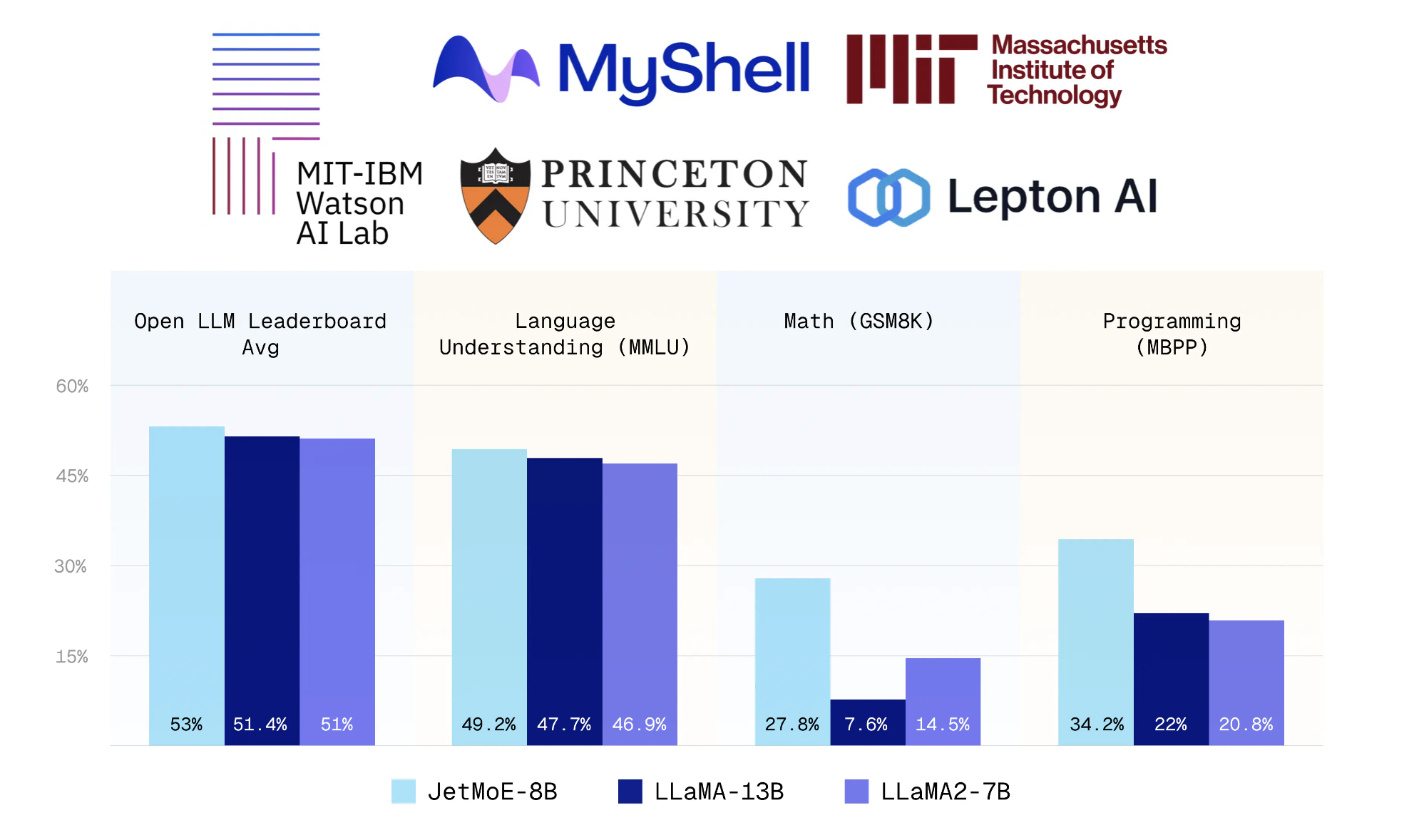
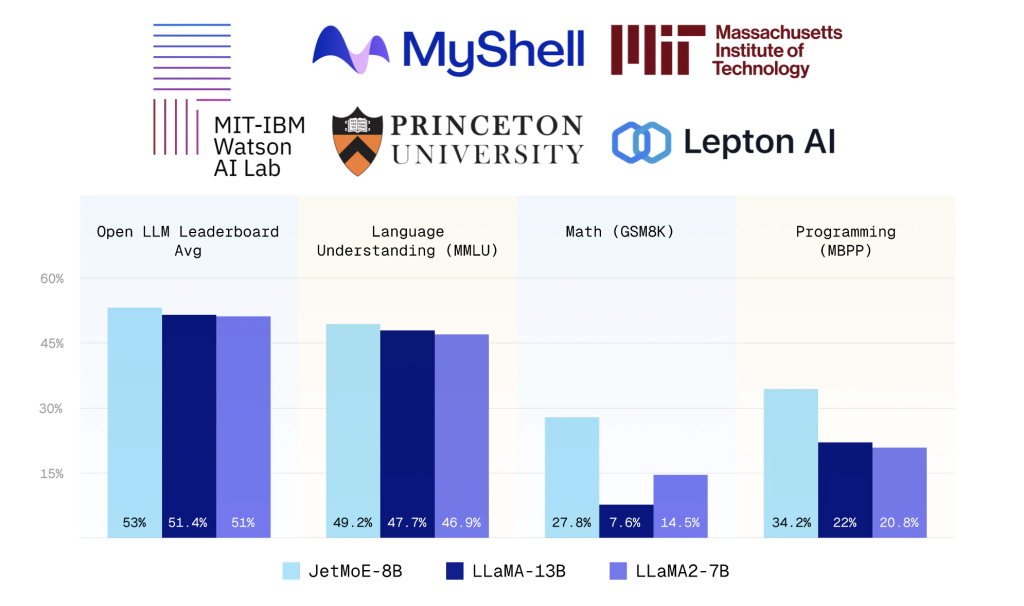
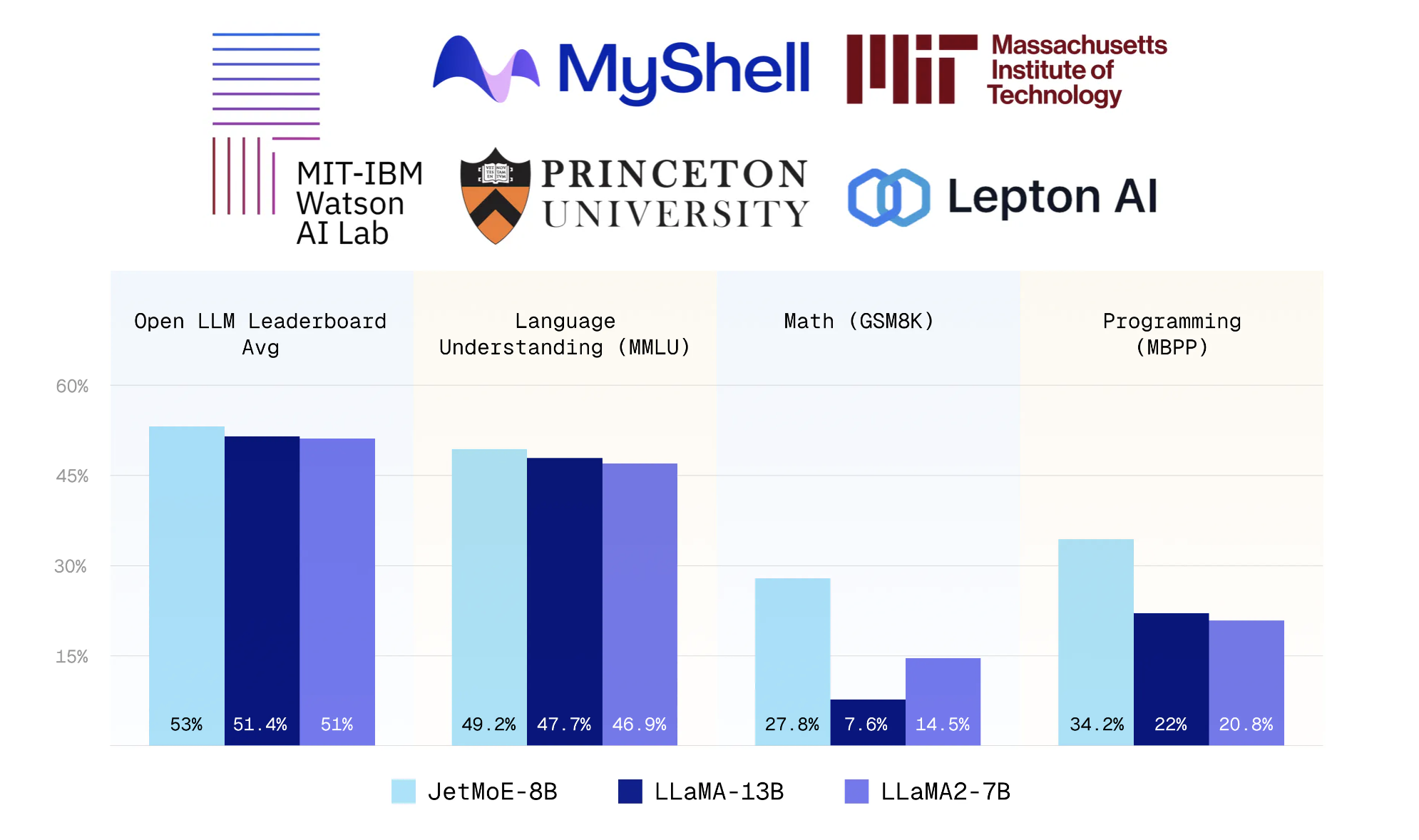
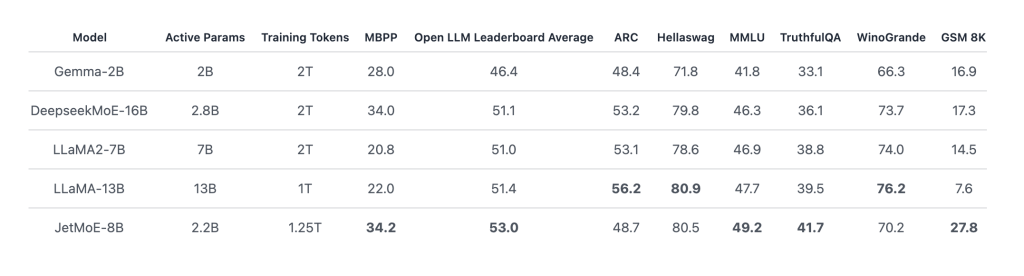
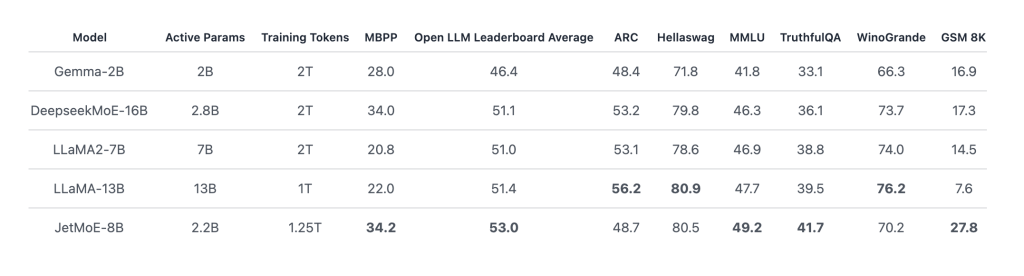
Ông nói với VentureBeat rằng ứng dụng hiện hỗ trợ một số mô hình AI nguồn mở làm mô hình cơ bản mà từ đó người dùng có thể bắt đầu cá nhân hóa trợ lý của họ, bao gồm các phiên bản nhỏ của DeepSeek và Llama của Meta.
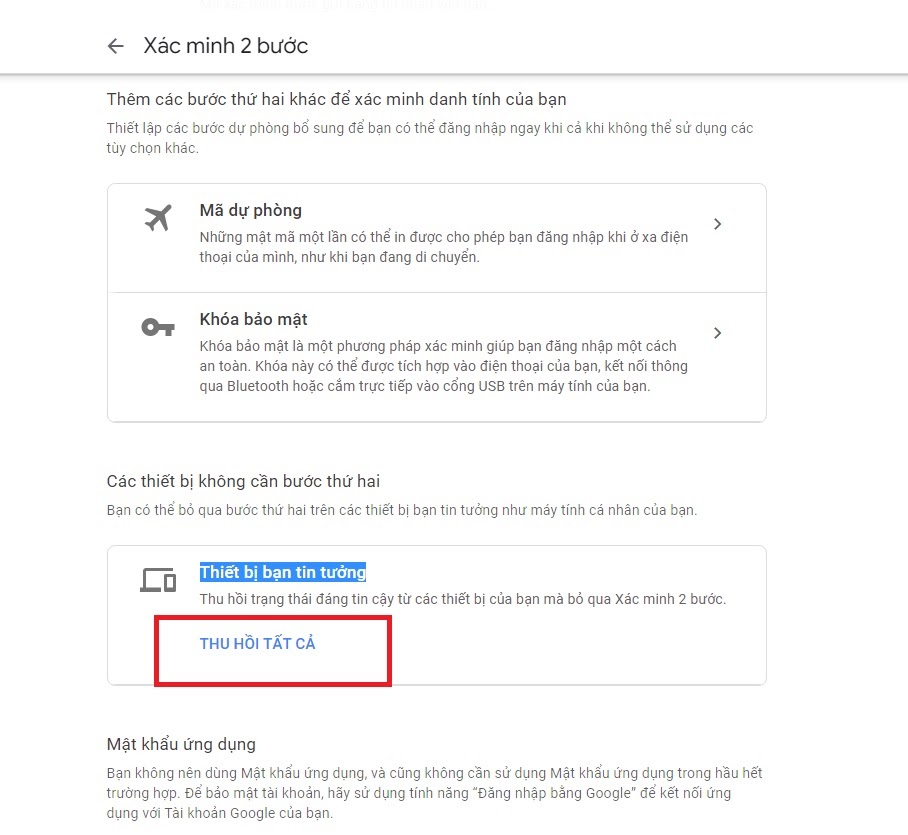
Sổ cái dựa trên Blockchain để xác thực và truy cập dữ liệu
Cơ sở hạ tầng của PIN AI được xây dựng trên các giao thức blockchain, đảm bảo tính bảo mật, minh bạch và khả năng kiểm soát của người dùng.
- Dữ liệu được lưu trữ cục bộ: Không giống như các hệ thống AI dựa trên đám mây, PIN AI giữ tất cả dữ liệu người dùng trên thiết bị cá nhân thay vì máy chủ tập trung.
- Môi trường thực thi đáng tin cậy (TEE) để xác thực: Thông tin xác thực và tính toán nhạy cảm xảy ra trong một vùng an toàn, ngăn chặn truy cập bên ngoài – ngay cả từ chính PIN AI.
- Sổ đăng ký Blockchain để minh bạch tài chính: Các hành động chính được xác thực trên chuỗi trong khi dữ liệu người dùng vẫn riêng tư và được lưu trữ cục bộ.
- Khả năng tương tác với các giao thức AI mới nổi: PIN AI được thiết kế để tích hợp với các dự án blockchain và AI phi tập trung trong tương lai, đảm bảo khả năng thích ứng lâu dài.
Bằng cách phi tập trung cơ sở hạ tầng AI, PIN AI nhằm mục đích cân bằng quyền riêng tư, bảo mật và hiệu quả, cho phép người dùng giữ quyền sở hữu dấu chân kỹ thuật số của họ đồng thời vẫn hưởng lợi từ tự động hóa và thông tin chi tiết do AI điều khiển.
“Chúng tôi đã thiết kế giao thức của mình xung quanh quyền riêng tư bằng cách sử dụng các phương pháp mật mã hiện đại như TTE,” Crapis nói. Không ai – thậm chí cả chúng tôi – có thể xem khóa xác thực của bạn,”
Tập trung vào AI dựa trên người dùng
Sự ra mắt của PIN AI diễn ra vào thời điểm mà những lo ngại về quyền riêng tư dữ liệu và độc quyền AI đang ở mức cao nhất mọi thời đại.
Đồng sáng lập Wu nhấn mạnh tầm quan trọng của chủ quyền dữ liệu, nói rằng, “Chúng tôi đang hợp nhất những người xây dựng và nhà phát triển AI nguồn mở để xây dựng nền tảng cho AI cá nhân mở, nơi người dùng sở hữu 100% AI.”
Sun giải thích tầm nhìn rộng hơn: “Hãy nghĩ về nó như J.A.R.V.I.S. từ Người Sắt – hệ thống điều hành trung thành nhất phát triển thành trợ lý AI cá nhân của bạn.”
Crapis tiếp tục trình bày chi tiết về phương pháp tiếp cận của PIN AI, nói rằng, “Chúng tôi đang tạo ra một ngân hàng dữ liệu cho phép bạn lấy lại dữ liệu cá nhân của mình từ các công ty công nghệ lớn – dữ liệu Google, dữ liệu Facebook, thậm chí cả Robinhood và dữ liệu tài chính – để AI cá nhân của bạn có thể chạy trên đó.”
Ngoài việc sử dụng cá nhân, PIN AI hình dung ra một mạng lưới các tác nhân AI cá nhân có thể tương tác với các dịch vụ bên ngoài thay mặt người dùng.
“AI cá nhân của bạn có thể phối hợp với các AI cá nhân khác, tương tác với AI doanh nghiệp và thậm chí tự động thực hiện các tác vụ như mua quà cho một người bạn dựa trên các cuộc trò chuyện trước đây,” Sun giải thích.
Những người đồng sáng lập PIN AI nói với VentureBeat rằng họ sẽ kiếm tiền bằng cách tính phí giao dịch để các tác nhân AI khác truy cập thông tin của người dùng – với sự cho phép của họ.
Điều gì tiếp theo cho PIN AI?
Với công nghệ AI đang phát triển nhanh chóng, PIN AI nhằm mục đích xác định tương lai của AI phi tập trung, được cá nhân hóa. Bằng cách kết hợp trí thông minh trên thiết bị, bảo mật blockchain và tích hợp nguồn mở, công ty cung cấp một giải pháp thay thế cho các mô hình AI do các công ty công nghệ lớn kiểm soát, đảm bảo rằng các cá nhân – chứ không phải các tập đoàn – sở hữu và kiểm soát dữ liệu của họ.
“Mô hình kinh doanh của chúng tôi rất đơn giản: Thay vì một công ty tập trung như Apple hoặc Google cắt một khoản lớn, chúng tôi lấy một khoản hoa hồng nhỏ trên các tương tác của tác nhân – giống như phí gas trên Ethereum,” Wu giải thích.
“Đây chỉ là sự khởi đầu,” Sun nói thêm. “Trong tương lai, AI của bạn sẽ kết nối với mọi thứ – máy tính để bàn, thiết bị thông minh, thậm chí cả robot hình người của bạn – trong khi vẫn giữ nguyên quyền riêng tư của bạn.”
Ứng dụng PIN AI hiện đã có sẵn, cung cấp một cấp độ mới về quyền riêng tư, bảo mật và cá nhân hóa trong trải nghiệm do AI điều khiển. Truy cập trang web của PIN AI hoặc tải xuống ứng dụng để bắt đầu xây dựng AI cá nhân của bạn.
Thông tin chi tiết hàng ngày về các trường hợp sử dụng kinh doanh với VB Daily
Nếu bạn muốn gây ấn tượng với sếp của mình, VB Daily sẽ giúp bạn. Chúng tôi cung cấp cho bạn thông tin nội bộ về những gì các công ty đang làm với AI tạo sinh, từ những thay đổi về quy định đến các triển khai thực tế, để bạn có thể chia sẻ thông tin chi tiết để có ROI tối đa.
Đọc Chính sách bảo mật của chúng tôi
Cảm ơn bạn đã đăng ký. Xem thêm bản tin VB tại đây.
Đã xảy ra lỗi.





















{kind=link}