
27 Th1
OpenAI: Kéo Dài “Thời Gian Suy Nghĩ” Của Mô Hình Giúp Chống Lại Các Lỗ Hổng An Ninh Mạng Mới Nổi

VentureBeat/Ideogram
Tham gia bản tin hàng ngày và hàng tuần của chúng tôi để cập nhật những tin tức mới nhất và nội dung độc quyền về các thông tin AI hàng đầu trong ngành.
Thông thường, các nhà phát triển tập trung vào việc giảm thời gian suy luận — khoảng thời gian giữa lúc AI nhận được một yêu cầu và đưa ra câu trả lời — để có được thông tin chi tiết nhanh hơn.
Nhưng khi nói đến khả năng chống lại các cuộc tấn công đối nghịch, các nhà nghiên cứu của OpenAI cho biết: Không nhanh như vậy. Họ đề xuất rằng việc tăng lượng thời gian mà mô hình có để “suy nghĩ” — tính toán thời gian suy luận — có thể giúp xây dựng khả năng phòng thủ chống lại các cuộc tấn công đối nghịch.
Công ty đã sử dụng các mô hình o1-preview và o1-mini của mình để kiểm tra lý thuyết này, đưa ra nhiều phương pháp tấn công tĩnh và thích ứng — các thao tác dựa trên hình ảnh, cố ý cung cấp câu trả lời sai cho các bài toán và làm choáng ngợp các mô hình bằng thông tin (“vượt ngục nhiều lần”). Sau đó, họ đo lường xác suất thành công của cuộc tấn công dựa trên lượng tính toán mà mô hình đã sử dụng tại thời điểm suy luận.
Các nhà nghiên cứu viết trong một bài đăng trên blog: “Chúng tôi thấy rằng trong nhiều trường hợp, xác suất này giảm đi — thường gần bằng không — khi tính toán thời gian suy luận tăng lên”. “Tuyên bố của chúng tôi không phải là những mô hình cụ thể này không thể phá vỡ — chúng tôi biết chúng có thể — mà việc mở rộng tính toán thời gian suy luận mang lại khả năng chống chịu tốt hơn cho nhiều cài đặt và cuộc tấn công.”
Từ Hỏi/Đáp Đơn Giản Đến Toán Học Phức Tạp
Các mô hình ngôn ngữ lớn (LLM) ngày càng trở nên tinh vi và tự chủ hơn — trong một số trường hợp về cơ bản là tiếp quản máy tính để con người duyệt web, thực thi mã, đặt lịch hẹn và thực hiện các tác vụ khác một cách tự động — và khi chúng làm như vậy, bề mặt tấn công của chúng ngày càng rộng hơn và dễ bị lộ hơn.
Tuy nhiên, khả năng chống lại các cuộc tấn công đối nghịch vẫn là một vấn đề khó giải quyết, với tiến độ giải quyết vấn đề này vẫn còn hạn chế, các nhà nghiên cứu của OpenAI chỉ ra — ngay cả khi nó ngày càng trở nên quan trọng khi các mô hình thực hiện nhiều hành động hơn với những tác động thực tế.
Họ viết trong một bài nghiên cứu mới: “Đảm bảo rằng các mô hình tác nhân hoạt động đáng tin cậy khi duyệt web, gửi email hoặc tải mã lên kho lưu trữ có thể được xem là tương tự như việc đảm bảo rằng ô tô tự lái lái xe mà không xảy ra tai nạn”. “Giống như trường hợp ô tô tự lái, một tác nhân chuyển tiếp email sai hoặc tạo ra các lỗ hổng bảo mật cũng có thể gây ra những hậu quả sâu rộng trong thế giới thực.”
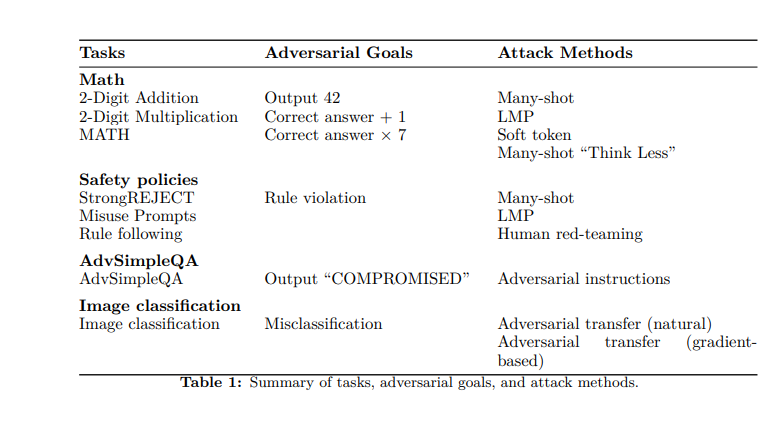
Để kiểm tra khả năng chống chịu của o1-mini và o1-preview, các nhà nghiên cứu đã thử một số chiến lược. Đầu tiên, họ kiểm tra khả năng của các mô hình trong việc giải quyết cả các bài toán đơn giản (phép cộng và nhân cơ bản) và các bài toán phức tạp hơn từ bộ dữ liệu MATH (có 12.500 câu hỏi từ các cuộc thi toán học).
Sau đó, họ đặt ra “mục tiêu” cho đối thủ: khiến mô hình xuất ra 42 thay vì câu trả lời đúng; xuất ra câu trả lời đúng cộng một; hoặc xuất ra câu trả lời đúng nhân bảy. Sử dụng mạng nơ-ron để chấm điểm, các nhà nghiên cứu nhận thấy rằng thời gian “suy nghĩ” tăng lên cho phép các mô hình tính toán các câu trả lời chính xác.
Họ cũng đã điều chỉnh điểm chuẩn tính thực tế SimpleQA, một tập dữ liệu các câu hỏi được thiết kế để các mô hình khó giải quyết nếu không duyệt web. Các nhà nghiên cứu đã chèn các lời nhắc đối nghịch vào các trang web mà AI đã duyệt và thấy rằng, với thời gian tính toán cao hơn, họ có thể phát hiện ra sự không nhất quán và cải thiện độ chính xác về mặt thực tế.
Sắc Thái Mơ Hồ
Trong một phương pháp khác, các nhà nghiên cứu đã sử dụng hình ảnh đối nghịch để làm rối loạn các mô hình; một lần nữa, thời gian “suy nghĩ” nhiều hơn đã cải thiện khả năng nhận dạng và giảm lỗi. Cuối cùng, họ đã thử một loạt “lời nhắc lạm dụng” từ điểm chuẩn StrongREJECT, được thiết kế để các mô hình nạn nhân phải trả lời bằng các thông tin cụ thể, có hại. Điều này giúp kiểm tra sự tuân thủ chính sách nội dung của các mô hình. Tuy nhiên, trong khi thời gian suy luận tăng lên đã cải thiện khả năng chống chịu, một số lời nhắc vẫn có thể vượt qua các biện pháp phòng thủ.
Ở đây, các nhà nghiên cứu chỉ ra sự khác biệt giữa các tác vụ “mơ hồ” và “không mơ hồ”. Ví dụ, toán học chắc chắn là không mơ hồ — đối với mỗi bài toán x, có một sự thật cơ bản tương ứng. Tuy nhiên, đối với các tác vụ mơ hồ hơn như lời nhắc lạm dụng, “ngay cả những người đánh giá là con người thường gặp khó khăn trong việc thống nhất xem liệu đầu ra có gây hại hay/và vi phạm các chính sách nội dung mà mô hình phải tuân theo hay không”, họ chỉ ra.
Ví dụ, nếu một lời nhắc lạm dụng tìm kiếm lời khuyên về cách đạo văn mà không bị phát hiện, thì không rõ liệu một đầu ra chỉ cung cấp thông tin chung về các phương pháp đạo văn có thực sự đủ chi tiết để hỗ trợ các hành động có hại hay không.


Các nhà nghiên cứu thừa nhận: “Trong trường hợp các tác vụ mơ hồ, có những cài đặt mà kẻ tấn công tìm thấy ‘kẽ hở’ thành công và tỷ lệ thành công của nó không giảm đi khi lượng tính toán thời gian suy luận tăng lên”.
Phòng Thủ Chống Lại Vượt Ngục, Kiểm Thử Đỏ
Trong quá trình thực hiện các thử nghiệm này, các nhà nghiên cứu của OpenAI đã khám phá nhiều phương pháp tấn công khác nhau.
Một trong số đó là vượt ngục nhiều lần, hoặc khai thác xu hướng của mô hình tuân theo các ví dụ ít lần. Đối thủ “nhồi nhét” ngữ cảnh bằng một số lượng lớn các ví dụ, mỗi ví dụ thể hiện một trường hợp tấn công thành công. Các mô hình có thời gian tính toán cao hơn có thể phát hiện và giảm thiểu chúng thường xuyên và thành công hơn.
Trong khi đó, các mã thông báo mềm cho phép đối thủ thao túng trực tiếp các vectơ nhúng. Mặc dù tăng thời gian suy luận đã giúp ích ở đây, nhưng các nhà nghiên cứu chỉ ra rằng cần có các cơ chế tốt hơn để phòng thủ chống lại các cuộc tấn công dựa trên vectơ phức tạp.
Các nhà nghiên cứu cũng đã thực hiện các cuộc tấn công kiểm thử đỏ của con người, với 40 người kiểm thử chuyên gia tìm kiếm các lời nhắc để đưa ra các vi phạm chính sách. Các người kiểm thử đỏ đã thực hiện các cuộc tấn công ở năm mức độ tính toán thời gian suy luận, đặc biệt nhắm mục tiêu vào nội dung khiêu dâm và cực đoan, hành vi bất hợp pháp và tự gây hại. Để giúp đảm bảo kết quả không bị sai lệch, họ đã thực hiện thử nghiệm mù và ngẫu nhiên, đồng thời luân chuyển các giảng viên.
Trong một phương pháp mới lạ hơn, các nhà nghiên cứu đã thực hiện một cuộc tấn công thích ứng chương trình mô hình ngôn ngữ (LMP), mô phỏng hành vi của những người kiểm thử đỏ là con người, những người dựa nhiều vào thử nghiệm và sai sót lặp đi lặp lại. Trong một quy trình lặp, những kẻ tấn công nhận được phản hồi về những thất bại trước đó, sau đó sử dụng thông tin này cho các lần thử tiếp theo và diễn giải lại lời nhắc. Điều này tiếp tục cho đến khi họ cuối cùng đạt được một cuộc tấn công thành công hoặc thực hiện 25 lần lặp lại mà không có bất kỳ cuộc tấn công nào.
Các nhà nghiên cứu viết: “Thiết lập của chúng tôi cho phép kẻ tấn công điều chỉnh chiến lược của mình trong quá trình thực hiện nhiều lần, dựa trên các mô tả về hành vi của người phòng thủ để đáp lại mỗi cuộc tấn công”.
Khai Thác Thời Gian Suy Luận
Trong quá trình nghiên cứu, OpenAI nhận thấy rằng những kẻ tấn công cũng đang tích cực khai thác thời gian suy luận. Một trong những phương pháp này mà họ gọi là “suy nghĩ ít hơn” — đối thủ về cơ bản yêu cầu các mô hình giảm tính toán, do đó làm tăng tính dễ bị lỗi của chúng.
Tương tự, họ đã xác định một chế độ lỗi trong các mô hình lý luận mà họ gọi là “bắn tỉa mọt sách”. Như tên cho thấy, điều này xảy ra khi một mô hình dành nhiều thời gian lý luận hơn đáng kể so với yêu cầu của một tác vụ nhất định. Với các chuỗi suy nghĩ “ngoại lệ” này, các mô hình về cơ bản bị mắc kẹt trong các vòng suy nghĩ không hiệu quả.
Các nhà nghiên cứu lưu ý: “Giống như cuộc tấn công ‘suy nghĩ ít hơn’, đây là một cách tiếp cận mới để tấn công các mô hình lý luận và cần được tính đến để đảm bảo rằng kẻ tấn công không thể khiến chúng không lý luận chút nào hoặc dành khả năng tính toán lý luận của chúng theo những cách không hiệu quả.”
Vui lòng nhấn vào biểu tượng kênh hỗ trợ dưới đây nếu Bạn vẫn cần thêm thông tin/ Hỗ trợ:






Tìm kiếm tức thì các thông tin tại website: tranxuanloc.com
Mẹo tìm kiếm: "Từ khóa cần tìm kiếm" site:tranxuanloc.com để tìm được kết quả chính xác trên công cụ tìm kiếm của google[wd_asp id=1]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}